
笔记
因果推断(8)——评估因果模型
评估因果模型
首先,我们要先明白,因果推断关注的是一个不可观察的量,即,那么我们怎么去评估这个模型是否良好。我们可以通过使用敏感度的聚合测度。即使你不能逐一估计敏感度,你也可以对一组单位估计它。
一般而言,就如机器学习的交叉验证一样,我们有训练集和测试集,测试集又有内部测试集和外部验证集一样。在因果学习中,我们则有非随机数据和随机数据。通常来说,由于随机数据是因果推断最核心的一个观念,然而现实里,随机数据及其地稀有并且代价高昂。所以我们会有很多的非随机数据,因此,我们用非随机数据来建立因果模型,而用随机数据进行评估。
回到异质性处理效应中的例子,即冰淇淋的销量,成本,假期,定价,温度。我们可以通过上调定价使得销量变化最小的策略来进行定价。现在我们假设有一个随机数据random_data和一个非随机数据data。他们两个数据都有这5个变量。
为了有可以比较的对象,我们会有一个线性模型构建,另外一个则用非参数的梯度提升的模型构建。
第一个模型我们用上一节的模型.
然后回顾一下,我们就可以通过偏微分获得敏感度预测:
第二个模型我们使用非参数梯度提升的模型:
我们可以通过调节一些超参数使得模型更优,详情在官方文档说明:GradientBoostingRegressor — scikit-learn 1.8.0 documentation
X = ["temp", "weekday", "cost", "price"]
y = "sales"
np.random.seed(1)
m2 = GradientBoostingRegressor()
m2.fit(data[X], data[y])
print("Train Score:", m2.score(data[X], data[y]))
print("Test Score:", m2.score(random_data[X], random_data[y]))
为了防止模型过拟合,我们可以计算训练集得分和测试集得分,如果训练集得分很高(0.95-1.00),但是测试集分数很低(<0.6),通常意味着过拟合。
在训练好我们的机器学习模型之后,我们也可以从回归模型中得到敏感度。同样,我们将采用数值近似
通常而言,我们还可以建立一个随机模型,这个模型仅输出随机数作为预测。当我们随机模型在评估指标上表现良好,这说明评估方法本身的有效性值得怀疑。
模型分段的敏感度
二元处理
首先需要明确一个定义,我们无法观察敏感度,因此没有简单的真实值可以比较。
我们构建处理敏感度模型,是为了寻找哪些单位对处理更加敏感,哪些单位对处理不敏感,从而实现个性化或者精准化的策略。而一个好的因果模型应该帮助我们发现哪些单位对策略的处理反应更好,哪些更差。所以它们应能根据单位对处理的弹性或敏感度将其分开。那么我们就有了一种想法,我们通过某种方式按敏感度高到低对单位进行排序。既然我们有预测的敏感度,我们可以用该预测对单位进行排序,并希望它也按照真实敏感度排序,但这是不可能在单个单位层实现的。所以我们会想着在一个群体中进行实现。如果我们数据中处理是随机分配的,估计一组单位的敏感度就很容易。我们所需要的只是比较处理组和未处理组之间的结果。
我们现在假设处理是二元变量,是打折,也就意味着价格要么高(未处理),要么低(处理)。在 Y 轴上绘制销售量,在 X 轴上绘制我们的每个模型,而具体的X轴是每个单位的id,然后我们用颜色表示价格。然后,我们可以在模型轴上将数据分成三个等大小的组。如果处理是随机分配的,我们可以很容易地为每个组估计平均处理效应.
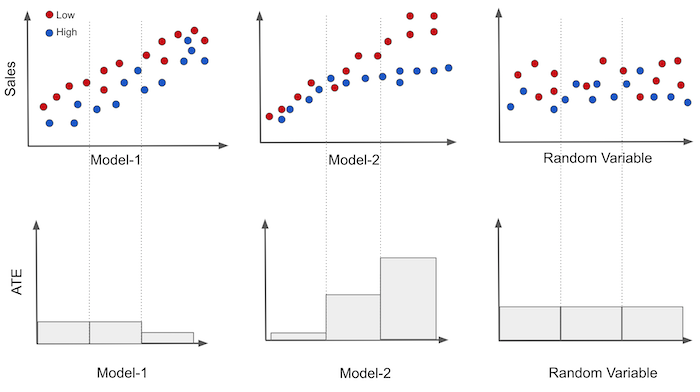
首先对于第一个模型,我们可以看到在预测销量方面很不错,价格低的处理会使得销量增高。但其产生的分组具有大致相同的处理效应,换句话说,三个分段里的敏感度都差不多,敏感度较低(除了第三组)
对于第二个模型,其在预测方面与第一个模型不相上下,或者说更好,另外,我们可以看到其产生的每个组都有不同的因果效应,表明该模型的确可以用于个性化。
对于第三个模型,其是一个随机生成的模型,当然,它既不能预测,也在分组内也是有一模一样的处理效应。
总的来说,我们会认为第二个模型优于第一个模型优于随机模型,第一个的模型比较是为了让我们选择一个模型,而第二个模型比较则是证明了我们的处理是具有有效性的。
连续处理
在连续处理上,我们可以使用单变量线性回归模型来估计敏感度:
当在某个组的样本内运行该模型,我们将估计该组内的敏感度。那么:
其中是处理的样本均值,是结果的样本均值。
那么现在我们可以将冰淇淋的价格变量作为处理进行考虑,同样的,我们也会将数据集划分为等大小的区间,并对每个区间应用敏感度函数。
def sensitivity(data, y, t):
return (np.sum((data[t] - data[t].mean())*(data[y] - data[y].mean())) /
np.sum((data[t] - data[t].mean())**2))
def sensitivity_by_band(df, pred, y, t, bands=10): #bands是分组数
return (df
.assign(**{f"{pred}_band":pd.qcut(df[pred], q=bands)})
.groupby(f"{pred}_band")
.apply(sensitivity, y=y, t=t))
fig, axs = plt.subplots(1, 3, sharey=True, figsize=(10, 4))
for m, ax in zip(["sensitivity_m_pred", "pred_m_pred", "rand_m_pred"], axs):
sensitivity_by_band(random_data, m, "sales", "price").plot.bar(ax=ax)
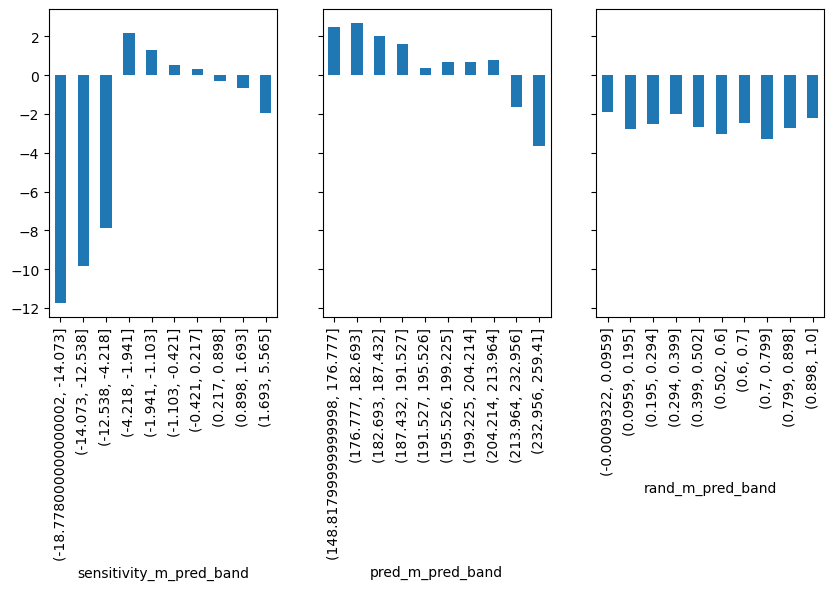
同样对每一个模型进行分析:
- 对于随机模型
rand_m,其估计的敏感度大致相同。 - 对于预测模型
pred_m,其能构建一些敏感度高的组和一些敏感度低的组。 - 对于因果模型
sensitivity_m,其它识别出一些极低敏感度的组,这里的极低是具有方向性的,而敏感度是高还是低,我觉得应该是看绝对值。
回忆一下,什么是预测模型,什么是因果模型。
预测模型我们值关注,因此我们关注的是,而在因果模型里,我们想要的是
但我们还是会面临选择,因为这次预测模型和因果模型各有优点,那我们应该如何选择?
累积敏感度曲线
比起用图,我觉得数学文字更加优雅和更加直观
我们在上面的图都看到,我们所得的敏感度并没有进行排序,也就是说,我们现在要将他们按照敏感度从高到低进行排序,我们不妨写成一个数列的样子:
然后,我们可以先计算的敏感度,然后将前两个组的单位组合成一个新的组计算的敏感度,然后依次计算,加到的敏感度,由于这样子有点乱,我重新定义一个数列进行这样的操作
所以累积敏感度定义为到第个单位为止估计的敏感度
然后通过运用这个思想,我们就可以做出一些很基本的判断:
-
首先:最明显的,当时,
-
其次,一个模型越好,其满足的程度越高。对于.
对于第二条,如果一个模型善于对敏感度排序,那么在前个样本中观察到的敏感度应高于在前个样本中观察到的敏感度。换句话说,如果看排名靠前的单位,它们应该比下面的单位有更高的敏感度。
def cumulative_sensitivity_curve(dataset, prediction, y, t, min_periods=30, steps=100):
size = dataset.shape[0]
# 对预测列进行排序
ordered_df = dataset.sort_values(prediction, ascending=False).reset_index(drop=True)
# 创造分组
n_rows = list(range(min_periods, size, size // steps)) + [size]
# 计算累计敏感度
return np.array([sensitivity(ordered_df.head(rows), y, t) for rows in n_rows])
# 创立图形
plt.figure(figsize=(10,6))
for m in ["sensitivity_m_pred", "pred_m_pred", "rand_m_pred"]:
cumu_sens = cumulative_sensitivity_curve(random_data, m, "sales", "price", min_periods=100, steps=100)
x = np.array(range(len(cumu_sens)))
plt.plot(x/x.max(), cumu_sens, label=m)
plt.hlines(sensitivity(random_data, "sales", "price"), 0, 1, linestyles="--", color="black", label="Avg. Sens.")
plt.xlabel("% of Top Sensitivity. Days")
plt.ylabel("Cumulative Sensitivity")
plt.title("Cumulative Sensitivity Curve")
plt.legend();
另外,我们设立了一个分组包含 min_periods 个单位的区段,为了减少样本量小导致曲线开头的敏感度的噪声影响。
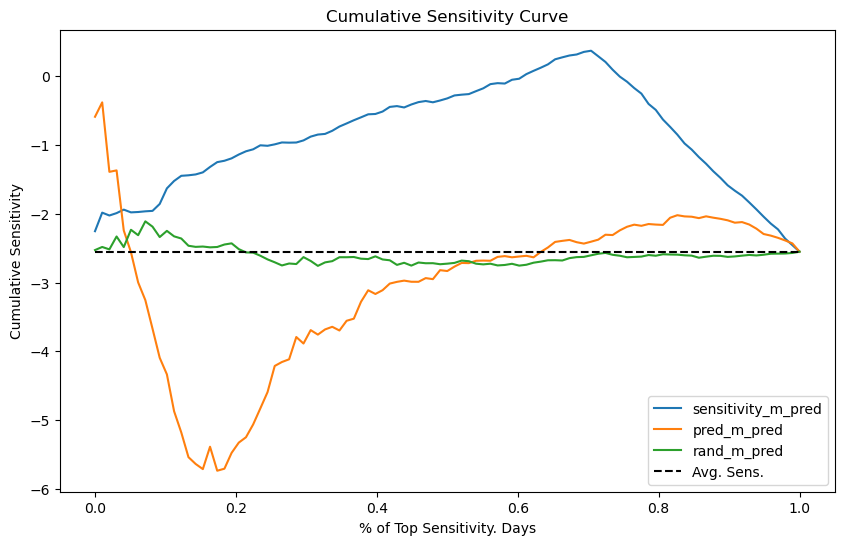
我们来详细解释这张图片传达的信息:
曲线的 X 轴表示我们处理的样本比例,而 Y 轴表示了累计敏感度。如果曲线在 40% 处的值为 -1,意味着排名前 40% 单位的敏感度是 -1。理想的曲线应从 Y 轴高处开始,并非常缓慢地下降到平均敏感度,表示我们可以处理很大比例的单位。所以对于优秀的因果模型,曲线在前期的累积斜率会非常陡峭,代表模型成功识别出了“对干预高度敏感”的核心人群。
- 随机模型
rand_m在平均敏感度附近震荡,意味着该模型无法找到敏感度不同于平均值的组 - 预测模型
pred_m,以相反的顺序排列敏感度,因为曲线很快就低于平均敏感度。不仅如此,它大约在50%的样本处就约收敛到平均敏感度 - 因果模型
sensitivity_m,起初累积敏感度先远离平均值增加,但随后达到一个极点,大约可以处理 75% 的单位,同时保持相当不错的敏感度。也就说这个模型能够识别出非常低敏感度(高价格敏感度)的日子。因此,只要我们在这些日子不提价,我们就可以在大多数样本(约 75%)中提价,同时仍保持低价格敏感度。
累积增益曲线
累积敏感度曲线仍然是一条难以理解的曲线。我们开始会想,如果我们不按相同的比例去计算累积敏感度会发生什么样的事情,我们开始去考虑样本比例。首先,我们将累积敏感度乘以样本比例,然后,我们将其与随机模型产生的理论曲线进行比较。这里产生的理论曲线是一条直线,是从 0 到平均处理效应的一条直线。因为对于任意一个点,其累积敏感度点等于平均处理效应,而样本比例 是单调递增的直线,所以理论曲线是一条从0开始,斜率为 ATE 的直线。
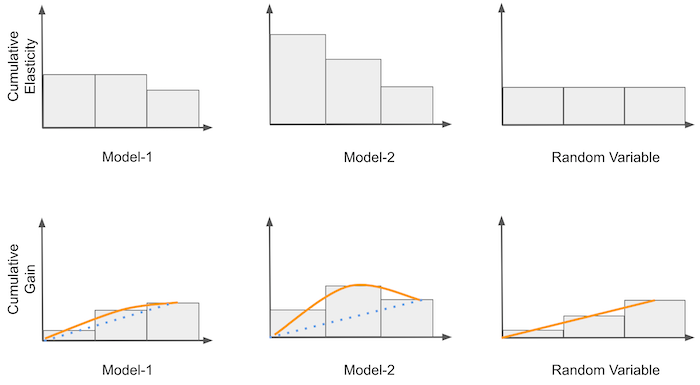
一旦我们有了理论随机曲线,我们就可以将其作为基准,与其他模型进行比较。所有曲线都从同一点开始并结束于同一点。而模型越善于排序敏感度,其曲线在 0 到 1 之间的部分就会越偏离随机直线。我们可以把累积增益看作因果模型的 ROC曲线。
还是回到我们一开始的数列:
我们仍然排序,生成累积敏感度点数列:
我们现在假定在在每一个点,其所占的样本比例,
所以我们可以生成累积增益点的数列,即:
def cumulative_gain(dataset, prediction, y, t, min_periods=30, steps=100):
size = dataset.shape[0]
ordered_df = dataset.sort_values(prediction, ascending=False).reset_index(drop=True)
n_rows = list(range(min_periods, size, size // steps)) + [size]
# 在累积敏感度上乘以样本比例
return np.array([sensitivity(ordered_df.head(rows), y, t) * (rows/size) for rows in n_rows])
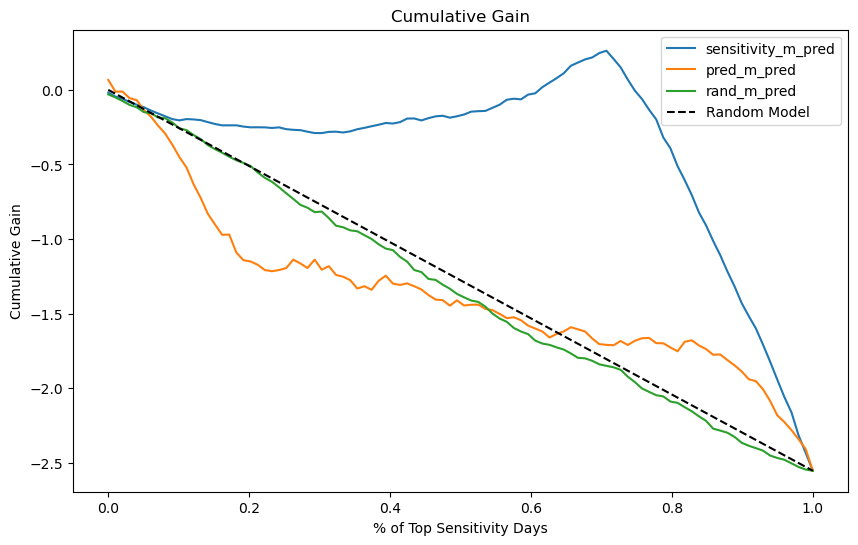
现在图里显示的很明显,因果模型(sensitivity_m)比另外两个模型好得多,因为它与随机曲线的偏离程度远大于 rand_m 和 pred_m。
考虑方差
当我们处理敏感度曲线时,我们需要考虑方差,不然我们不知道它是否是显著的。尤其是因为所有这些曲线都使用了线性回归理论,因此在它们周围加入置信区间应该相当容易。
为此,我们计算累积敏感度的简单线性回归参数的置信区间。
首先计算截距,和每个样本的残差
其中:
- 和 分别为因变量和自变量在第 个样本上的观测值
- 和 分别为它们的样本均值
- 为总样本量
那么剩余标准差为
标准误为:
def sensitivity_ci(df, y, t, z=1.96):
n = df.shape[0]
t_bar = df[t].mean()
beta1 = sensitivity(df, y, t)
beta0 = df[y].mean() - beta1 * t_bar
e = df[y] - (beta0 + beta1*df[t])
se = np.sqrt(((1/(n-2))*np.sum(e**2))/np.sum((df[t]-t_bar)**2))
return np.array([beta1 - z*se, beta1 + z*se])
使用方式只需要把上面return一行的sensitivity替换为sensitivity_ci即可
在实际应用中,评估排序曲线时,更稳妥的是 bootstrap 或稳健标准误来求置信区间
AUUC
在有了累积增益曲线之后,一个自然的想法是,既然图形能比较模型排序的好坏,那我们也可以把这条曲线压缩成一个数值指标。AUUC(Area Under the Uplift Curve)就是累积增益曲线下方的面积。
假设模型按照预测敏感度或预测处理效应从高到低排序,在样本比例为 的位置,前 比例样本的累积增益为
其中 表示排名前 比例样本中估计出来的平均处理效应或敏感度。对于二元处理,它可以写成:
其中 表示按模型排序后排名前 的样本集合。对于连续处理, 可以用前面提到的组内线性回归斜率来估计。
AUUC 的定义为:
在实际计算中,我们通常只有有限个点,所以使用梯形法近似(连续转离散):
AUUC 越大,说明模型越能把高处理效应的样本排在前面。直观地说,如果模型排序很好,那么曲线会在前半段快速上升,从而获得更大的面积;如果模型只是随机排序,那么它的累积增益曲线会接近随机基准线。
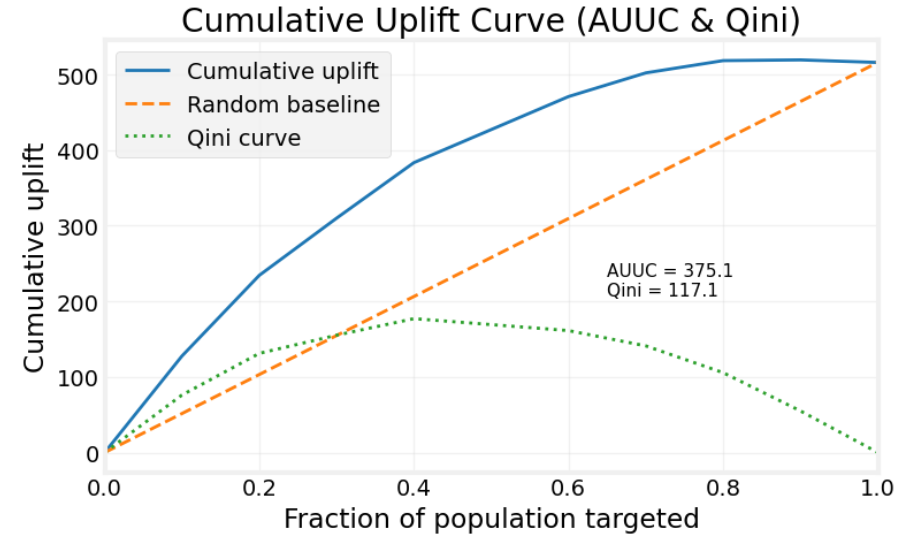
这里需要注意一个方向问题:AUUC 一般而言越大越好,所以我们必须先明确什么叫做更好的处理效应(与我们的目的紧密相关)。如果处理效应是正向收益,例如优惠券带来购买率提升,那么直接按 从大到小排序即可;如果我们关注的是价格敏感度这类可能为负的量,就需要先统一方向,例如,把更值得处理的样本定义为 更大,或者按业务目标重新定义排序分数。
def cumulative_gain_curve(dataset, prediction, y, t, min_periods=30, steps=100):
size = dataset.shape[0]
ordered_df = dataset.sort_values(prediction, ascending=False).reset_index(drop=True)
step = max(size // steps, 1)
n_rows = list(range(min_periods, size, step)) + [size]
p = np.array(n_rows) / size
gain = np.array([
sensitivity(ordered_df.head(rows), y, t) * (rows / size)
for rows in n_rows
])
# 加入原点,方便计算曲线下面积
return np.r_[0, p], np.r_[0, gain]
def auuc_score(dataset, prediction, y, t):
p, gain = cumulative_gain_curve(dataset, prediction, y, t)
return np.trapezoid(gain, p)
Qini系数
AUUC 衡量的是累积增益曲线本身的面积,但它没有直接扣除随机排序带来的基础收益。Qini 系数则进一步把随机基准线作为参照,衡量模型相对于随机分配策略多出来的面积。
在随机排序下,排名前 比例样本的平均处理效应应该等于总体平均处理效应 ,因此随机基准曲线为:
其中
也就是全样本上的平均处理效应或平均敏感度。
Qini 系数定义为模型累积增益曲线与随机基准线之间的面积(如上图):
离散情形下同样可以用梯形法计算:
它的解释更接近“模型排序相对于随机排序多带来了多少增益”:
- :模型优于随机排序。
- :模型基本等同于随机排序。
- :模型排序方向可能是错的,甚至比随机排序更差。
所以,AUUC 看的是曲线整体面积,而 Qini 系数看的是曲线相对于随机基准线的额外面积。两者都依赖同一条累积增益曲线,但 Qini 更强调的是超过随机策略的部分,因此更适合比较不同模型的排序能力。
对应代码可以写成:
def qini_score(dataset, prediction, y, t):
p, gain = cumulative_gain_curve(dataset, prediction, y, t)
avg_effect = sensitivity(dataset, y, t)
random_gain = p * avg_effect
return np.trapezoid(gain - random_gain, p)
有时候我们会使用标准化 Qini 系数,即把模型的 Qini 面积除以理想模型的 Qini 面积:
这样做可以使得结果更具有比较性。但还是之前我们提到的,在真实世界中,个体层面的真实处理效应通常不可观察,因此“理想模型”往往只能在模拟数据中直接构造,或者通过特定的经验上界来近似。