本笔记基于Bayesian Data Analysis Third Edition, Andrew Gelman et. al. 学习编写,由于是英文教材,可能在学习过程中一些翻译或者内容有误,如有问题或错误,可以发送至邮箱[email protected]
首先考虑的是二项式分布,在这里面,我们观察到的 y y y
首先对于二项式分布,我们常常记做: X ∼ B i n ( n , θ ) X \sim Bin(n,\theta) X ∼ B in ( n , θ )
因此,我们也可以写作:
p ( y ∣ θ ) = B i n ( y ∣ n , θ ) = ( n y ) θ y ( 1 − θ ) n − y p(y|\theta) = Bin(y|n,\theta) = \bigg(
\begin{matrix} n \\ y
\end{matrix} \bigg) \theta^y(1-\theta)^{n-y} p ( y ∣ θ ) = B in ( y ∣ n , θ ) = ( n y ) θ y ( 1 − θ ) n − y 我们看到这个式子里,还另外依靠 n n n n n n
在这种情况下,我们之前谈过,我们可以做一个很简单的先验假设,其是均匀分布的 (至于这个合理性,我们会在后面谈到如何检验先验合理性时再谈). 所以,我们就可以通过贝叶斯法则进行计算:
p ( θ ∣ y ) ∝ p ( θ ) p ( y ∣ θ ) = ( n y ) θ y ( 1 − θ ) n − y ∝ θ y ( 1 − θ ) n − y \begin{aligned}
p(\theta|y) &\propto p(\theta) p(y|\theta) \\
&= \bigg(
\begin{matrix} n \\ y
\end{matrix} \bigg) \theta^y(1-\theta)^{n-y} \\
&\propto \theta^y(1-\theta)^{n-y}
\end{aligned} p ( θ ∣ y ) ∝ p ( θ ) p ( y ∣ θ ) = ( n y ) θ y ( 1 − θ ) n − y ∝ θ y ( 1 − θ ) n − y 由于 ( n y ) \bigg( \begin{matrix} n \\ y \end{matrix} \bigg) ( n y ) θ \theta θ θ \theta θ
θ ∣ y ∼ B e t a ( y + 1 , n − y + 1 ) \theta|y \sim Beta(y+1, n-y+1) θ ∣ y ∼ B e t a ( y + 1 , n − y + 1 )
这里我们先对之前提到的一些分布进行解释 (正态分布由于每个人都听过,这里默认都知道其形式):
均匀分布(Uniform):
记作: θ ∼ U ( α , β ) \theta \sim U(\alpha,\beta) θ ∼ U ( α , β )
密度方程: p ( θ ) = 1 β − α p(\theta)=\frac{1}{\beta-\alpha} \\ p ( θ ) = β − α 1
均值:E ( θ ) = α + β 2 E(\theta)=\frac{\alpha+\beta}{2}\\ E ( θ ) = 2 α + β
方差: v a r ( θ ) = ( β − α ) 2 12 var(\theta)=\frac{(\beta-\alpha)^2}{12}\\ v a r ( θ ) = 12 ( β − α ) 2
Beta分布:
记作:θ ∼ B e t a ( α , β ) \theta \sim Beta(\alpha,\beta) θ ∼ B e t a ( α , β )
密度方程:p ( θ ) = Γ ( α + β ) Γ ( α ) Γ ( β ) θ α − 1 ( 1 − θ ) β − 1 , θ ∈ [ 0 , 1 ] p(\theta) = \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta^{\alpha-1}(1-\theta)^{\beta-1}, \theta \in [0,1] \\ p ( θ ) = Γ ( α ) Γ ( β ) Γ ( α + β ) θ α − 1 ( 1 − θ ) β − 1 , θ ∈ [ 0 , 1 ]
均值:E ( θ ) = α α + β E(\theta)=\frac{\alpha}{\alpha+\beta}\\ E ( θ ) = α + β α
方差:v a r ( θ ) = α β ( α + β ) 2 ( α + β + 1 ) var(\theta) = \frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)}\\ v a r ( θ ) = ( α + β ) 2 ( α + β + 1 ) α β
众数:m o d e ( θ ) = α − 1 α + β − 2 mode(\theta) = \frac{\alpha-1}{\alpha+\beta-2} \\ m o d e ( θ ) = α + β − 2 α − 1
其他分布在以后提到的时候在进行书写
在书中的P30-31,有一个很有意思的历史故事,其是对贝叶斯台球问题的一个阐述及解答
那么现在,我们有了后验分布的基本形式了,那么接下来,我们来看先验预测分布:
p ( y ) = ∫ 0 1 ( n y ) θ y ( 1 − θ ) n − y d θ = 1 n + 1 for y = 0 , … , n \begin{aligned}
p(y) &= \int_0^1 \bigg( \begin{matrix} n \\ y \end{matrix} \bigg) \theta^y(1-\theta)^{n-y}d\theta \\
&= \frac{1}{n+1} \quad \text{for }y=0,\dots,n
\end{aligned} p ( y ) = ∫ 0 1 ( n y ) θ y ( 1 − θ ) n − y d θ = n + 1 1 for y = 0 , … , n 我们现在来证明这个式子:
我们还是一样的,使用Beta函数的性质进行计算(原因很简单,通过Γ ( ⋅ ) \Gamma(\cdot) Γ ( ⋅ )
那么就有
∫ 0 1 θ y ( 1 − θ ) n − y d θ = B ( y + 1 , n − y + 1 ) \int_0^1 \theta^y (1-\theta)^{n-y} d\theta = B(y+1, n-y+1) ∫ 0 1 θ y ( 1 − θ ) n − y d θ = B ( y + 1 , n − y + 1 ) 于是乎
B ( y + 1 , n − y + 1 ) = Γ ( y + 1 ) Γ ( n − y + 1 ) Γ ( y + 1 + n − y + 1 ) = y ! ⋅ ( n − y ) ! ( n + 1 ) ! B(y+1, n-y+1) = \frac{\Gamma(y+1)\Gamma(n-y+1)}{\Gamma(y+1 + n-y+1)} = \frac{y! \cdot (n-y)!}{(n+1)!} B ( y + 1 , n − y + 1 ) = Γ ( y + 1 + n − y + 1 ) Γ ( y + 1 ) Γ ( n − y + 1 ) = ( n + 1 )! y ! ⋅ ( n − y )! 所以原式就等于
p ( y ) = [ n ! y ! ( n − y ) ! ] ⋅ [ y ! ⋅ ( n − y ) ! ( n + 1 ) ! ] = 1 n + 1 \begin{aligned}
p(y) &= \left[ \frac{n!}{y!(n-y)!} \right] \cdot \left[ \frac{y! \cdot (n-y)!}{(n+1)!} \right] \\
&=\frac{1}{n+1}
\end{aligned} p ( y ) = [ y ! ( n − y )! n ! ] ⋅ [ ( n + 1 )! y ! ⋅ ( n − y )! ] = n + 1 1 接下来,我们来计算后验预测分布:
P r ( y ~ = 1 ∣ y ) = ∫ 0 1 P r ( y ~ = 1 ∣ y , θ ) p ( θ ∣ y ) d θ = ∫ 0 1 θ p ( θ ∣ y ) d θ = E ( θ ∣ y ) = y + 1 y + 1 + n − y + 1 = y + 1 n + 2 \begin{aligned}
Pr(\tilde y = 1 |y) &= \int_0^1 Pr(\tilde y=1 |y,\theta)p(\theta|y) d \theta \\
&= \int_0^1 \theta p(\theta|y) d\theta \\
&= E(\theta|y) \\
&= \frac{y+1}{y+1+n-y+1} \\
&= \frac{y+1}{n+2}
\end{aligned} P r ( y ~ = 1∣ y ) = ∫ 0 1 P r ( y ~ = 1∣ y , θ ) p ( θ ∣ y ) d θ = ∫ 0 1 θ p ( θ ∣ y ) d θ = E ( θ ∣ y ) = y + 1 + n − y + 1 y + 1 = n + 2 y + 1 这第四个等号我们用到了Beta分布的期望,我们现在来证明这个期望:我们用到一个更为普遍的Beta分布,即B e t a ( p , q ) Beta(p,q) B e t a ( p , q )
在证明之前,我们先了解一个Beta分布的核心性质:其与 Gamma 函数的联系:
B ( p , q ) = Γ ( p ) Γ ( q ) Γ ( p + q ) B(p, q) = \frac{\Gamma(p)\Gamma(q)}{\Gamma(p+q)} B ( p , q ) = Γ ( p + q ) Γ ( p ) Γ ( q ) 有了这条联系后,我们证明这个会变得十分简单
E ( x ∣ y ) = ∫ 0 1 x x p − 1 ( 1 − x ) q − 1 ∫ 0 1 x p − 1 ( 1 − x ) q − 1 d x d x = ∫ 0 1 x p ( 1 − x ) q − 1 d x ∫ 0 1 x p − 1 ( 1 − x ) q − 1 d x = B ( p + 1 , q ) B ( p , q ) = Γ ( p + 1 ) Γ ( q ) Γ ( p + q + 1 ) ⋅ Γ ( p + q ) Γ ( p ) Γ ( q ) = p Γ ( p ) Γ ( q ) ( p + q ) Γ ( p + q ) ⋅ Γ ( p + q ) Γ ( p ) Γ ( q ) = p p + q \begin{aligned}
E(x|y) &= \int_0^1 x \frac{x^{p-1}(1-x)^{q-1}}{\int_0^1 x^{p-1}(1-x)^{q-1}dx} dx \\
&= \frac{\int_0^1x^{p}(1-x)^{q-1}dx}{\int_0^1 x^{p-1}(1-x)^{q-1}dx} \\
&= \frac{B(p+1,q)}{B(p,q)} \\
&= \frac{\Gamma(p+1)\Gamma(q)}{\Gamma(p+q+1)}\cdot \frac{\Gamma(p+q)}{\Gamma(p)\Gamma(q)} \\
&= \frac{p\Gamma(p)\Gamma(q)}{(p+q)\Gamma(p+q)}\cdot \frac{\Gamma(p+q)}{\Gamma(p)\Gamma(q)} \\
&= \frac{p}{p+q}
\end{aligned} E ( x ∣ y ) = ∫ 0 1 x ∫ 0 1 x p − 1 ( 1 − x ) q − 1 d x x p − 1 ( 1 − x ) q − 1 d x = ∫ 0 1 x p − 1 ( 1 − x ) q − 1 d x ∫ 0 1 x p ( 1 − x ) q − 1 d x = B ( p , q ) B ( p + 1 , q ) = Γ ( p + q + 1 ) Γ ( p + 1 ) Γ ( q ) ⋅ Γ ( p ) Γ ( q ) Γ ( p + q ) = ( p + q ) Γ ( p + q ) p Γ ( p ) Γ ( q ) ⋅ Γ ( p ) Γ ( q ) Γ ( p + q ) = p + q p 对于这个基于均匀分布作为先验分布的结果,就被叫做了拉普拉斯连续法则 ,在极端情况,当 y = 0 y=0 y = 0 y = n y=n y = n 1 n + 2 \frac{1}{n+2} n + 2 1 n + 1 n + 2 \frac{n+1}{n+2} n + 2 n + 1
首先我们来看方差的表达式:
v a r ( θ ) = E ( v a r ( θ ∣ y ) ) + v a r ( E ( θ ∣ y ) ) var(\theta) = E(var(\theta|y)) + var(E(\theta|y)) v a r ( θ ) = E ( v a r ( θ ∣ y )) + v a r ( E ( θ ∣ y )) 这条式子一个有趣的点在于左边是先验的方差,而右边的第二项是后验的方差,也就是说:后验方差一般小于先验方差 ,后验方差的大小取决于后验均值在可能数据分布上的变异程度,其变异程度越大,我们降低 θ \theta θ
比如在上面的二项式例子里,我们知道了,其均值为 1/2,方差为 1/12,后验的均值 y + 1 n + 2 \frac{y+1}{n+2} n + 2 y + 1 y / n y/n y / n
后验分布以代表先验信息和数据分布的折中点为中心,随着样本量的增大,其折中更大程度由数据所控制。
后验分布 p ( θ ∣ y ) p(\theta|y) p ( θ ∣ y ) θ \theta θ
但在实际分析中,我们经常还需要一些数值摘要,这些摘要可以分成两类:
位置摘要 :
后验均值:E ( θ ∣ y ) E(\theta|y) E ( θ ∣ y )
后验中位数:满足 P r ( θ ≤ m ∣ y ) = 0.5 Pr(\theta \leq m|y)=0.5 P r ( θ ≤ m ∣ y ) = 0.5 m m m
后验众数:也就是后验密度最高的位置,经常记作 MAP(在计算策略里非常重要)
不确定性摘要 :
后验标准差:衡量后验分布的分散程度
四分位距:q 0.75 − q 0.25 q_{0.75}-q_{0.25} q 0.75 − q 0.25
后验分位数和后验区间
这些摘要的含义并不完全一样。后验均值是参数的后验期望,适合用于平方损失下的点估计;后验中位数是把后验概率质量一分为二的位置,适合描述分布的中心位置;后验众数则是后验密度最高的点,也可以理解为在模型和数据给定后最“密集”的参数值。
在前面的二项式例子中,如果使用均匀先验,则有
θ ∣ y ∼ B e t a ( y + 1 , n − y + 1 ) \theta|y \sim Beta(y+1,n-y+1) θ ∣ y ∼ B e t a ( y + 1 , n − y + 1 ) 所以后验均值是
E ( θ ∣ y ) = y + 1 n + 2 E(\theta|y)=\frac{y+1}{n+2} E ( θ ∣ y ) = n + 2 y + 1 如果 0 < y < n 0<y<n 0 < y < n
mode ( θ ∣ y ) = ( y + 1 ) − 1 ( y + 1 ) + ( n − y + 1 ) − 2 = y n \operatorname{mode}(\theta|y)=\frac{(y+1)-1}{(y+1)+(n-y+1)-2}=\frac{y}{n} mode ( θ ∣ y ) = ( y + 1 ) + ( n − y + 1 ) − 2 ( y + 1 ) − 1 = n y 也就是说,在均匀先验下,后验众数与二项分布参数的最大似然估计相同,都是样本比例 y / n y/n y / n y / n y/n y / n y + 1 n + 2 \frac{y+1}{n+2} n + 2 y + 1 1 / 2 1/2 1/2
除了点估计,更重要的是报告后验不确定性。贝叶斯分析中常用的是后验可信区间 ,它描述的是在当前模型、先验和数据给定后,参数落在某个区间内的后验概率 (应注意的是,与频率学派中的 p p p
例如,一个 100 ( 1 − α ) % 100(1-\alpha)\% 100 ( 1 − α ) %
[ q α / 2 , q 1 − α / 2 ] \left[q_{\alpha/2},q_{1-\alpha/2}\right] [ q α /2 , q 1 − α /2 ] 其中
P r ( θ ≤ q α / 2 ∣ y ) = α 2 , P r ( θ ≤ q 1 − α / 2 ∣ y ) = 1 − α 2 Pr(\theta \leq q_{\alpha/2}|y)=\frac{\alpha}{2},
\quad
Pr(\theta \leq q_{1-\alpha/2}|y)=1-\frac{\alpha}{2} P r ( θ ≤ q α /2 ∣ y ) = 2 α , P r ( θ ≤ q 1 − α /2 ∣ y ) = 1 − 2 α 因此这个区间中间包含
P r ( q α / 2 ≤ θ ≤ q 1 − α / 2 ∣ y ) = 1 − α Pr(q_{\alpha/2}\leq \theta \leq q_{1-\alpha/2}|y)=1-\alpha P r ( q α /2 ≤ θ ≤ q 1 − α /2 ∣ y ) = 1 − α 的后验概率质量。比如 95 % 95\% 95% [ q 0.025 , q 0.975 ] [q_{0.025},q_{0.975}] [ q 0.025 , q 0.975 ] 2.5 % 2.5\% 2.5%
这里需要注意,贝叶斯中的可信区间 和频率学派中的置信区间 不是同一个概念。贝叶斯可信区间可以直接解释为:
P r ( θ ∈ C ∣ y ) = 0.95 Pr(\theta \in C|y)=0.95 P r ( θ ∈ C ∣ y ) = 0.95 也就是在已经看到数据 y y y θ \theta θ C C C 0.95 0.95 0.95 95 % 95\% 95%
如果我们不能直接计算后验分布的分位数,也可以通过后验模拟 (这个后面会有一整大章来进行解读)来近似。假设从后验分布中抽到了 S S S
θ ( 1 ) , θ ( 2 ) , … , θ ( S ) \theta^{(1)},\theta^{(2)},\dots,\theta^{(S)} θ ( 1 ) , θ ( 2 ) , … , θ ( S ) 把它们从小到大排序后,用经验分位数来近似中心后验区间。
中心后验区间 :由后验分位数定义,两边尾部概率相同。最高后验密度区 :由后验密度高度定义,区域内任意一点的后验密度都不低于区域外任意一点。
最高后验密度区常被记作 HPD region 或 HDI,可以用下面的形式理解:
C c = { θ : p ( θ ∣ y ) ≥ c } C_c=\{\theta:p(\theta|y)\geq c\} C c = { θ : p ( θ ∣ y ) ≥ c } 其中阈值 c c c
∫ C c p ( θ ∣ y ) d θ = 1 − α \int_{C_c}p(\theta|y)d\theta=1-\alpha ∫ C c p ( θ ∣ y ) d θ = 1 − α 即,HPD 区域不是看左右尾部概率,而是从后验密度最高的地方开始往外添加概率质量,直到装够 100 ( 1 − α ) % 100(1-\alpha)\% 100 ( 1 − α ) %
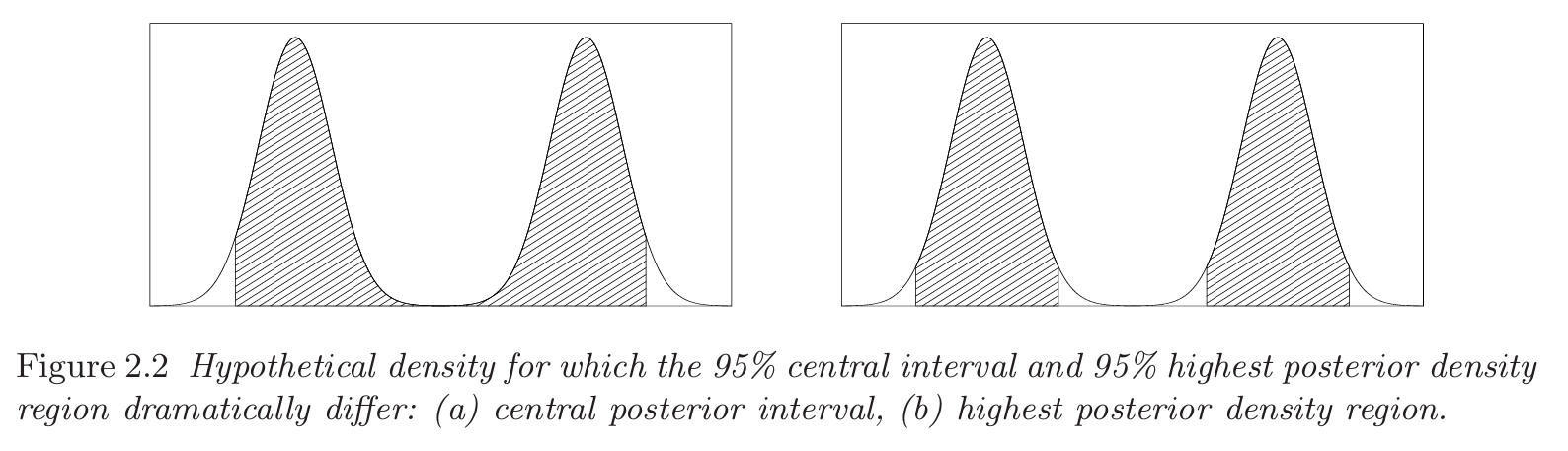
图 2.2 的左边是 95 % 95\% 95% 中心后验区间 。由于它只根据左右分位数决定端点,所以即使中间有一段后验密度接近 0,仍然会被夹在这个连续区间里。这样做的缺点是:区间看起来像在说中间的值也很可信,但实际上中间可能几乎没有后验概率。
图 2.2 的右图是 95 % 95\% 95% 最高后验密度区 。在二项分布里,由于后验分布是双峰的,密度最高的区域集中在左右两个峰附近,所以 HPD 区域自然分成了两个不相连的区间。它比中心区间更麻烦,但更准确地表达了这个后验分布的结构:参数更可能出现在两个峰附近,而不是出现在中间的低密度区域。
对于我个人的理解,最高后验密度区最简单的概念就是在后验密度区域内,不存在任意一点的后验概率是低于后验密度区域以外的后验密度,即 P r θ ∈ C ( θ ∣ y ) > P r θ ∉ C ( θ ∣ y ) Pr_{\theta \in C}(\theta|y) > Pr_{\theta \notin C}(\theta|y) P r θ ∈ C ( θ ∣ y ) > P r θ ∈ / C ( θ ∣ y )
如果后验分布是单峰且对称 的,那么中心后验区间和最高后验密度区通常会重合;如果后验分布偏斜 ,二者会明显不同;如果后验分布多峰 ,HPD 区域甚至可能不是一个连续区间。因此,对于多峰后验分布,我们不应该只用一个区间进行概括,而是画出整个后验密度,或者分别报告几个高密度区域。
可以这样区分二者:
概念
定义依据
形式
优点
局限
中心后验区间
后验分位数
通常是一个连续区间
解释直接,计算简单,模拟时容易得到
对偏斜或多峰分布可能误导
最高后验密度区
后验密度高度
可能是不连续区域
保留“哪些值更密集”的信息,常是给定概率质量下更短的区域
计算更复杂,多峰时不如单个区间直观
还有一个重要补充:中心后验区间在单调变换下比较自然,例如对 θ \theta θ
还记得上面提到的,我们使用均匀分布来假设先验,那么它到底合不合理,我们就要来进行检验了。
我们看回均匀检验,其形式如下:
θ ∼ U ( 0 , 1 ) \theta \sim U(0,1) θ ∼ U ( 0 , 1 ) 这相当于认为在观察数据之前,θ \theta θ [ 0 , 1 ] [0,1] [ 0 , 1 ] 信息先验分布 。
如何来理解先验分布:
总体解释 :先验分布代表一组可能的参数值,当前问题中的 θ \theta θ 知识状态解释 :先验分布表达我们在看数据之前关于 θ \theta θ θ \theta θ
对于很多问题,比如估计一个新工业流程的失败概率,我们并没有一个真实存在的“参数总体”可以抽样,因此更常用的是第二种解释。先验分布应该覆盖所有合理的参数值,但不一定要非常集中在真实值附近。只要数据量足够大,似然函数通常会压过多数合理先验的影响。
前面已经证明过,在二项式模型中,如果使用均匀先验,那么先验预测分布为
p ( y ) = 1 n + 1 , y = 0 , 1 , … , n p(y)=\frac{1}{n+1},\quad y=0,1,\dots,n p ( y ) = n + 1 1 , y = 0 , 1 , … , n 也就是说,在观察数据之前,y y y n + 1 n+1 n + 1 y y y n n n
但是,均匀先验并不是一个在所有问题中都“客观无信息”的先验。所谓“如果什么都不知道,就赋予均匀分布”的思想,常被称为无差别原则 或者理由不足原则 。它的问题是:均匀性依赖于参数化方式 。如果对 θ \theta θ logit ( θ ) \operatorname{logit}(\theta) logit ( θ )
我们比较熟悉二项式分布,所以我们接着继续考虑,二项式似然为
p ( y ∣ θ ) = ( n y ) θ y ( 1 − θ ) n − y ∝ θ y ( 1 − θ ) n − y p(y|\theta)=\binom{n}{y}\theta^y(1-\theta)^{n-y}
\propto \theta^y(1-\theta)^{n-y} p ( y ∣ θ ) = ( y n ) θ y ( 1 − θ ) n − y ∝ θ y ( 1 − θ ) n − y 把它看成关于 θ \theta θ
θ a ( 1 − θ ) b \theta^a(1-\theta)^b θ a ( 1 − θ ) b 所以,为了得到一个计算方便的先验族,我们可以选择同样形式 的先验:
p ( θ ) ∝ θ α − 1 ( 1 − θ ) β − 1 p(\theta)\propto \theta^{\alpha-1}(1-\theta)^{\beta-1} p ( θ ) ∝ θ α − 1 ( 1 − θ ) β − 1 即
θ ∼ B e t a ( α , β ) \theta \sim Beta(\alpha,\beta) θ ∼ B e t a ( α , β ) 其中 α , β \alpha,\beta α , β 超参数 (Hyperparameter) ,它们并不是模型中的随机观测值,而是控制先验分布形状的参数。
现在我们用这个当作先验,然后用贝叶斯公式计算后验分布:
p ( θ ∣ y ) ∝ p ( y ∣ θ ) p ( θ ) ∝ θ y ( 1 − θ ) n − y θ α − 1 ( 1 − θ ) β − 1 = θ y + α − 1 ( 1 − θ ) n − y + β − 1 \begin{aligned}
p(\theta|y)
&\propto p(y|\theta)p(\theta) \\
&\propto \theta^y(1-\theta)^{n-y}
\theta^{\alpha-1}(1-\theta)^{\beta-1}\\
&=\theta^{y+\alpha-1}(1-\theta)^{n-y+\beta-1}
\end{aligned} p ( θ ∣ y ) ∝ p ( y ∣ θ ) p ( θ ) ∝ θ y ( 1 − θ ) n − y θ α − 1 ( 1 − θ ) β − 1 = θ y + α − 1 ( 1 − θ ) n − y + β − 1 即
θ ∣ y ∼ B e t a ( α + y , β + n − y ) \theta|y \sim Beta(\alpha+y,\beta+n-y) θ ∣ y ∼ B e t a ( α + y , β + n − y ) 这说明,在二项式模型中,Beta 先验和二项式似然结合后,后验仍然是 Beta 分布。
这种性质叫做共轭性 :
如果某一类先验分布 和某一类似然函数结合 之后,得到的后验分布与先验分布仍然属于同一类先验分布 ,那么这类先验就是该似然的共轭先验 。
比如:
似然函数
先验
后验
二项分布
Beta分布
Beta分布
多项式分布
Dirichlet分布
Dirichlet分布
Poisson分布
Gamma分布
Gamma分布
已知方差的正态分布
正态分布
正态分布
从指数形式看,先验
p ( θ ) ∝ θ α − 1 ( 1 − θ ) β − 1 p(\theta)\propto \theta^{\alpha-1}(1-\theta)^{\beta-1} p ( θ ) ∝ θ α − 1 ( 1 − θ ) β − 1 很像一个已经观察到 α − 1 \alpha-1 α − 1 β − 1 \beta-1 β − 1 α − 1 \alpha-1 α − 1 β − 1 \beta-1 β − 1
不过在使用后验均值时,另一个更常见的解释是把 α + β \alpha+\beta α + β
E ( θ ) = α α + β E(\theta)=\frac{\alpha}{\alpha+\beta} E ( θ ) = α + β α 后验均值为
E ( θ ∣ y ) = α + y α + β + n E(\theta|y)=\frac{\alpha+y}{\alpha+\beta+n} E ( θ ∣ y ) = α + β + n α + y 它可以写成先验均值和样本比例的加权平均 :
E ( θ ∣ y ) = α + β α + β + n ⋅ α α + β + n α + β + n ⋅ y n \begin{aligned}
E(\theta|y) &=\frac{\alpha+\beta}{\alpha+\beta+n}
\cdot \frac{\alpha}{\alpha+\beta} +\frac{n}{\alpha+\beta+n}\cdot \frac{y}{n}
\end{aligned} E ( θ ∣ y ) = α + β + n α + β ⋅ α + β α + α + β + n n ⋅ n y 所以后验均值一定位于先验均值 α α + β \frac{\alpha}{\alpha+\beta} α + β α y n \frac{y}{n} n y
我们可以获得更加普适的规则:后验均值 = 先验信息和数据信息的加权平均 。
当 n n n α + β α + β + n \frac{\alpha+\beta}{\alpha+\beta+n} α + β + n α + β n n n n α + β + n \frac{n}{\alpha+\beta+n} α + β + n n y / n y/n y / n
因为后验分布是
B e t a ( α + y , β + n − y ) Beta(\alpha+y,\beta+n-y) B e t a ( α + y , β + n − y ) 根据 Beta 分布方差公式,有
var ( θ ∣ y ) = ( α + y ) ( β + n − y ) ( α + β + n ) 2 ( α + β + n + 1 ) \operatorname{var}(\theta|y) =
\frac{(\alpha+y)(\beta+n-y)}
{(\alpha+\beta+n)^2(\alpha+\beta+n+1)} var ( θ ∣ y ) = ( α + β + n ) 2 ( α + β + n + 1 ) ( α + y ) ( β + n − y ) 如果记
μ y = E ( θ ∣ y ) = α + y α + β + n \mu_y=E(\theta|y)=\frac{\alpha+y}{\alpha+\beta+n} μ y = E ( θ ∣ y ) = α + β + n α + y 那么也可以写成
var ( θ ∣ y ) = μ y ( 1 − μ y ) α + β + n + 1 \operatorname{var}(\theta|y) =
\frac{\mu_y(1-\mu_y)}{\alpha+\beta+n+1} var ( θ ∣ y ) = α + β + n + 1 μ y ( 1 − μ y ) 当 α , β \alpha,\beta α , β n n n
E ( θ ∣ y ) ≈ y n E(\theta|y)\approx \frac{y}{n} E ( θ ∣ y ) ≈ n y 并且
var ( θ ∣ y ) ≈ 1 n y n ( 1 − y n ) \operatorname{var}(\theta|y)
\approx
\frac{1}{n}\frac{y}{n}\left(1-\frac{y}{n}\right) var ( θ ∣ y ) ≈ n 1 n y ( 1 − n y ) 因此后验方差以 1 / n 1/n 1/ n
另外,根据中心极限定理,在大样本下我们可以用正态分布近似后验分布:
θ − E ( θ ∣ y ) var ( θ ∣ y ) ∣ y → N ( 0 , 1 ) \frac{\theta-E(\theta|y)}
{\sqrt{\operatorname{var}(\theta|y)}}\mid y
\rightarrow N(0,1) var ( θ ∣ y ) θ − E ( θ ∣ y ) ∣ y → N ( 0 , 1 ) 但对于二项式概率参数 θ \theta θ [ 0 , 1 ] [0,1] [ 0 , 1 ]
logit ( θ ) = log θ 1 − θ \operatorname{logit}(\theta)=\log\frac{\theta}{1-\theta} logit ( θ ) = log 1 − θ θ 这个变换把参数空间从 [ 0 , 1 ] [0,1] [ 0 , 1 ] ( − ∞ , ∞ ) (-\infty,\infty) ( − ∞ , ∞ )
θ = exp ( x ) 1 + exp ( x ) \theta=\frac{\exp(x)}{1+\exp(x)} θ = 1 + exp ( x ) exp ( x ) 回到原始概率尺度。
共轭先验的优点主要有三个:
计算方便,后验分布通常有解析形式。
解释清楚,很多共轭先验都能解释为“额外数据”。
可以作为更复杂模型的构件。
但是共轭先验不是必须的。如果真实的先验知识和共轭族明显不一致,就应该使用更合理的非共轭先验。非共轭先验不会带来新的贝叶斯概念问题,因为仍然是
p ( θ ∣ y ) ∝ p ( y ∣ θ ) p ( θ ) p(\theta|y)\propto p(y|\theta)p(\theta) p ( θ ∣ y ) ∝ p ( y ∣ θ ) p ( θ ) 只是计算会更困难,往往需要数值积分、后验模拟或者 MCMC 方法。
一个实际的折中方式是:从共轭模型出发理解问题,再根据具体背景逐步放宽先验形式。比如,如果单个 Beta 分布太简单,可以考虑多个 Beta 分布的混合,从而表示更复杂甚至多峰的先验信念。
这里我们会谈及充分统计量,如果不熟悉,可以直接跳跃。
充分统计量(Sufficient Statistics):若给定统计量的值,样本联合密度的条件分布与未知参数无关,则这个统计量为充分统计量。
对于充分统计量的验证,我们有一条定理:因子分解定理(Factorization theorem) :设总体概率函数为 f ( x ; θ ) f(x;\theta) f ( x ; θ ) x 1 , x 2 , … , x n x_1,x_2,\dots,x_n x 1 , x 2 , … , x n T = T ( x 1 , … , x n ) T = T(x_1,\dots,x_n) T = T ( x 1 , … , x n ) g ( t , θ ) g(t,\theta) g ( t , θ ) h ( x 1 , … , x n ) h(x_1,\dots,x_n) h ( x 1 , … , x n ) θ \theta θ ( x 1 , … , x n ) (x_1,\dots,x_n) ( x 1 , … , x n ) f ( x 1 , … , x n , θ ) = g ( T ( x 1 , … , x n ) , θ ) h ( x 1 , … , x n ) f(x_1,\dots,x_n,\theta) = g(T(x1,\dots,x_n),\theta)h(x_1,\dots,x_n) f ( x 1 , … , x n , θ ) = g ( T ( x 1 , … , x n ) , θ ) h ( x 1 , … , x n )
假设独立同分布数据 y 1 , … , y n y_1,\dots,y_n y 1 , … , y n
p ( y i ∣ θ ) = f ( y i ) g ( θ ) exp ( ϕ ( θ ) T u ( y i ) ) p(y_i|\theta)=f(y_i)g(\theta)\exp\left(\phi(\theta)^T u(y_i)\right) p ( y i ∣ θ ) = f ( y i ) g ( θ ) exp ( ϕ ( θ ) T u ( y i ) ) 那么联合似然为
p ( y ∣ θ ) = ∏ i = 1 n f ( y i ) g ( θ ) exp ( ϕ ( θ ) T u ( y i ) ) ∝ g ( θ ) n exp ( ϕ ( θ ) T ∑ i = 1 n u ( y i ) ) \begin{aligned}
p(y|\theta)
&=\prod_{i=1}^n f(y_i)g(\theta)
\exp\left(\phi(\theta)^T u(y_i)\right)\\
&\propto g(\theta)^n
\exp\left(\phi(\theta)^T \sum_{i=1}^n u(y_i)\right)
\end{aligned} p ( y ∣ θ ) = i = 1 ∏ n f ( y i ) g ( θ ) exp ( ϕ ( θ ) T u ( y i ) ) ∝ g ( θ ) n exp ( ϕ ( θ ) T i = 1 ∑ n u ( y i ) ) 记
t ( y ) = ∑ i = 1 n u ( y i ) t(y)=\sum_{i=1}^n u(y_i) t ( y ) = i = 1 ∑ n u ( y i ) 上面这条等式是唯一与数据信息所相关的。
则似然可以写成
p ( y ∣ θ ) ∝ g ( θ ) n exp ( ϕ ( θ ) T t ( y ) ) p(y|\theta)\propto g(\theta)^n\exp\left(\phi(\theta)^T t(y)\right) p ( y ∣ θ ) ∝ g ( θ ) n exp ( ϕ ( θ ) T t ( y ) ) 这说明数据关于 θ \theta θ t ( y ) t(y) t ( y ) t ( y ) t(y) t ( y ) θ \theta θ
如果我们选择如下先验:
p ( θ ) ∝ g ( θ ) η exp ( ϕ ( θ ) T ν ) p(\theta)\propto g(\theta)^\eta
\exp\left(\phi(\theta)^T \nu\right) p ( θ ) ∝ g ( θ ) η exp ( ϕ ( θ ) T ν ) 那么后验为
p ( θ ∣ y ) ∝ g ( θ ) η + n exp ( ϕ ( θ ) T ( ν + t ( y ) ) ) p(\theta|y)\propto
g(\theta)^{\eta+n}
\exp\left(\phi(\theta)^T(\nu+t(y))\right) p ( θ ∣ y ) ∝ g ( θ ) η + n exp ( ϕ ( θ ) T ( ν + t ( y )) ) 它仍然属于同一个形式,因此这是自然共轭先验。这里的更新方式也非常直观:
η → η + n , ν → ν + t ( y ) \eta \rightarrow \eta+n,\quad
\nu \rightarrow \nu+t(y) η → η + n , ν → ν + t ( y ) 也就是说,后验超参数等于先验超参数加上样本量和充分统计量。
指数分布:
记作: θ ∼ E x p o n ( β ) \theta\sim Expon(\beta) θ ∼ E x p o n ( β )
密度函数: p ( θ ) = β e − β θ , θ > 0 , same as Gamma ( α = 1 , β ) p(\theta) = \beta e^{-\beta\theta}, \theta >0, \text{same as Gamma}(\alpha = 1, \beta) p ( θ ) = β e − β θ , θ > 0 , same as Gamma ( α = 1 , β )
期望:E ( θ ) = 1 β E(\theta) = \frac{1}{\beta} E ( θ ) = β 1
方差:v a r ( θ ) = 1 β 2 var(\theta) = \frac{1}{\beta^2} v a r ( θ ) = β 2 1
众数: 0
Gamma分布
记作:θ ∼ G a m m a ( α , β ) \theta\sim Gamma(\alpha,\beta) θ ∼ G amma ( α , β ) α \alpha α β \beta β
密度函数: p ( θ ) = β α Γ ( α ) θ α − 1 e − β θ p(\theta) = \frac{\beta^{\alpha}}{\Gamma(\alpha)}\theta^{\alpha-1}e^{-\beta\theta} \\ p ( θ ) = Γ ( α ) β α θ α − 1 e − β θ
期望:E ( θ ) = α β E(\theta) = \frac{\alpha}{\beta} E ( θ ) = β α
方差:v a r ( θ ) = α β 2 var(\theta) = \frac{\alpha}{\beta^2} v a r ( θ ) = β 2 α
众数:m o d e ( θ ) = α − 1 β , α ≥ 1 mode(\theta)=\frac{\alpha-1}{\beta}, \alpha \ge 1 m o d e ( θ ) = β α − 1 , α ≥ 1
对二项式或者伯努利模型来说,
p ( y i ∣ θ ) = θ y i ( 1 − θ ) 1 − y i p(y_i|\theta)=\theta^{y_i}(1-\theta)^{1-y_i} p ( y i ∣ θ ) = θ y i ( 1 − θ ) 1 − y i 可以改写为
p ( y i ∣ θ ) = ( 1 − θ ) exp ( y i log θ 1 − θ ) p(y_i|\theta) =(1-\theta)\exp\left(y_i\log\frac{\theta}{1-\theta}\right) p ( y i ∣ θ ) = ( 1 − θ ) exp ( y i log 1 − θ θ ) 所以它的自然参数是
logit ( θ ) = log θ 1 − θ \operatorname{logit}(\theta)=\log\frac{\theta}{1-\theta} logit ( θ ) = log 1 − θ θ 充分统计量是成功次数
t ( y ) = ∑ i = 1 n y i t(y)=\sum_{i=1}^n y_i t ( y ) = i = 1 ∑ n y i 即在二项式模型中,所有关于 θ \theta θ y y y n n n