本笔记基于Bayesian Data Analysis Third Edition, Andrew Gelman et. al. 学习编写,由于是英文教材,可能在学习过程中一些翻译或者内容有误,如有问题或错误,可以发送至邮箱[email protected]
那么,我们讲完了很多模型的设置,一般为了方便,我们会选用共轭先验来进行计算。在这种情况下,我们需要知道的是,我们假设先验的时候,其可以包括很多信息,但同时,它也可以几乎没有信息(因为我们无法观察),也可以介乎两者之间。但我们之前说过,后验是先验和数据的折衷,数据少时,先验会明显影响后验;数据多时,似然通常会主导后验。
我们这里选用一个例子讲述有信息的先验:
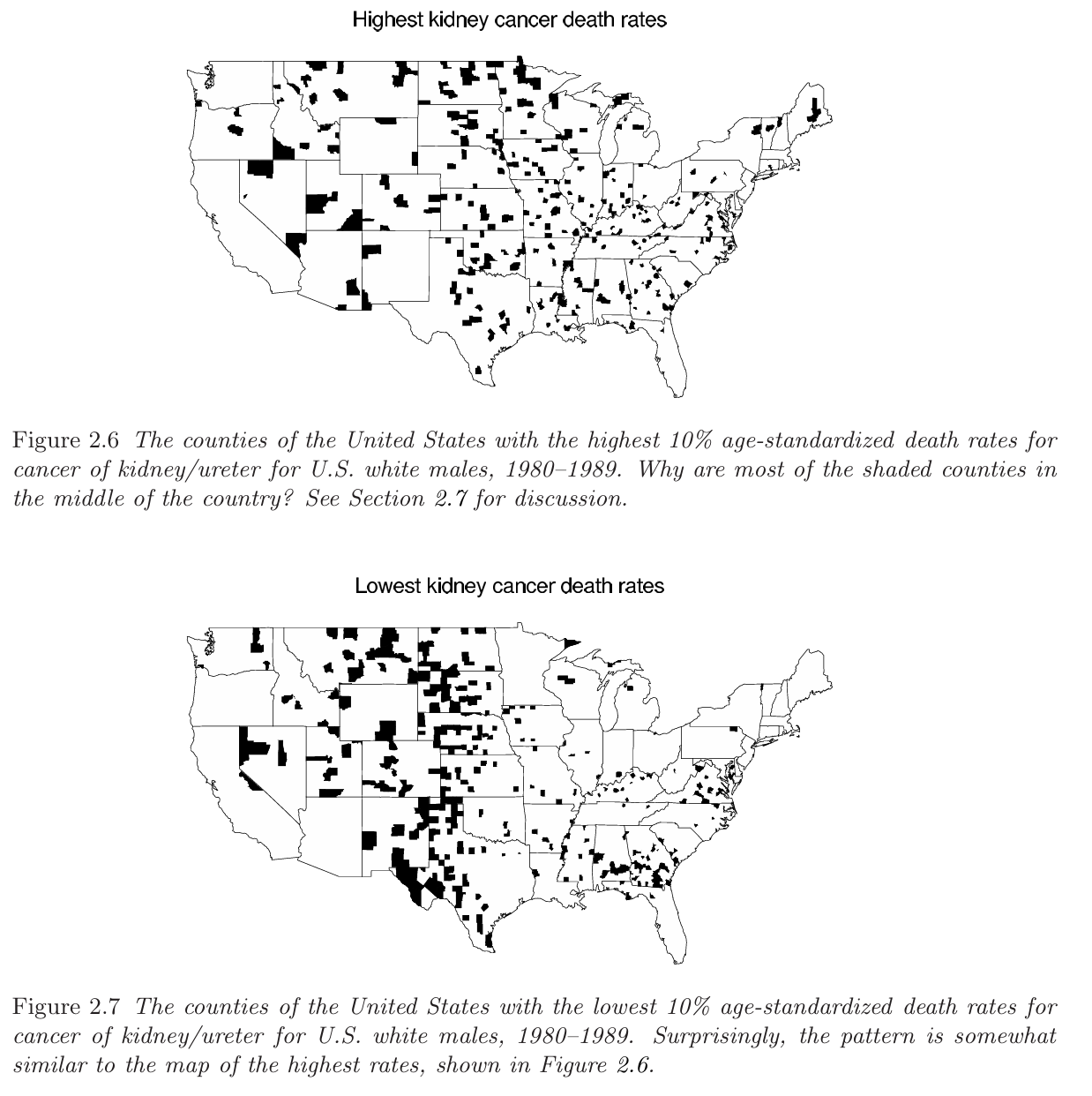
背景:美国各县在 1980-1989 年间白人男性肾脏/输尿管癌死亡率。原始地图显示:死亡率最高的 10% 县很多在美国中部;但再看死亡率最低的 10% 县,也有很多在美国中部。
如果我们熟悉美国地理的就知道,美国的常住人口基本位于东部和西部,而中部的居民比较少(由于环境不如东西部好),因此我们真的可以说中部地区XX县的肾癌死亡率高或者低吗,显然不可以,因为中部有很多人口很少的县,且肾癌本身处于罕见疾病,小县在十年内可能出现 0 例死亡,也可能偶然出现 1 例死亡。由于分母很小,1 例死亡就会让原始死亡率显得很高;0 例死亡又会让原始死亡率显得很低。接下来我们构建模型来做一示范。需要注意的是,由于这些地区之前本身有异质性,因此使用分层(hierarchal model )会更加合适,但为了简单,我们暂时不考虑。
对于罕见疾病(比如癌症),我们通畅会使用泊松分布来进行拟合发病率。
对每个县 j j j
y j y_j y j n j n_j n j ω j \omega_j ω j 10 n j 10n_j 10 n j
于是我们便可以写出似然:
y j ∣ ω j ∼ Poisson ( 10 n j ω j ) y_j \mid \omega_j \sim \operatorname{Poisson}(10n_j\omega_j) y j ∣ ω j ∼ Poisson ( 10 n j ω j ) 而对于总体的肾癌死亡率为y j 10 n j \frac{y_j}{10n_j} 10 n j y j
为了估计每个县的死亡率,我们使用Gamma先验
ω j ∼ Gamma ( α , β ) \omega_j \sim \operatorname{Gamma}(\alpha,\beta) ω j ∼ Gamma ( α , β ) p ( ω j ∣ α , β ) = β α Γ ( α ) ω j α − 1 exp ( − β ω j ) , ω j > 0 p(\omega_j\mid \alpha,\beta) =
\frac{\beta^\alpha}{\Gamma(\alpha)}
\omega_j^{\alpha-1}\exp(-\beta\omega_j),
\quad \omega_j>0 p ( ω j ∣ α , β ) = Γ ( α ) β α ω j α − 1 exp ( − β ω j ) , ω j > 0 在这个参数下,根据Gamma分布的性质,我们写下期望和方差:
E ( ω j ) = α β , var ( ω j ) = α β 2 E(\omega_j)=\frac{\alpha}{\beta},
\qquad
\operatorname{var}(\omega_j)=\frac{\alpha}{\beta^2} E ( ω j ) = β α , var ( ω j ) = β 2 α 在这里,我们可以通过设置不同的 α , β \alpha, \beta α , β α = 20 , β = 430000 \alpha=20,\quad \beta=430000 α = 20 , β = 430000
此时:
E ( ω j ) = 20 430000 = 4.65 × 10 − 5 sd ( ω j ) = 20 430000 = 1.04 × 10 − 5 E(\omega_j)=\frac{20}{430000}=4.65\times 10^{-5} \\
\operatorname{sd}(\omega_j) =\frac{\sqrt{20}}{430000} =1.04\times 10^{-5} E ( ω j ) = 430000 20 = 4.65 × 1 0 − 5 sd ( ω j ) = 430000 20 = 1.04 × 1 0 − 5 在这里,这个期望由县级死亡率数据的总体特征来近似确定。换句话说,我们把原有的信息纳入了我们的模型。
此时,我们就可以计算后验分布:
p ( ω j ∣ y j ) ∝ p ( y i ∣ ω j ) p ( ω j ) = Poisson ( 10 n j ω j ) Gamma ( α , β ) ∝ ω j α + y j − 1 exp [ − ( β + 10 n j ) ω j ] = Gamma ( 20 + y j , 430000 + 10 n j ) \begin{aligned}
p(\omega_j\mid y_j) &\propto p(y_i|\omega_j)p(\omega_j)\\
&= \operatorname{Poisson}(10n_j\omega_j)\operatorname{Gamma}(\alpha,\beta)\\
&\propto \omega_j^{\alpha+y_j-1} \exp[-(\beta+10n_j)\omega_j] \\
&= \operatorname{Gamma}(20+y_j,430000+10n_j)
\end{aligned} p ( ω j ∣ y j ) ∝ p ( y i ∣ ω j ) p ( ω j ) = Poisson ( 10 n j ω j ) Gamma ( α , β ) ∝ ω j α + y j − 1 exp [ − ( β + 10 n j ) ω j ] = Gamma ( 20 + y j , 430000 + 10 n j ) 此时,后验均值和方差为:
E ( ω j ∣ y j ) = 20 + y j 430000 + 10 n j var ( ω j ∣ y j ) = 20 + y j ( 430000 + 10 n j ) 2 E(\omega_j\mid y_j) = \frac{20+y_j}{430000+10n_j} \\
\operatorname{var}(\omega_j\mid y_j) = \frac{20+y_j}{(430000+10n_j)^2} E ( ω j ∣ y j ) = 430000 + 10 n j 20 + y j var ( ω j ∣ y j ) = ( 430000 + 10 n j ) 2 20 + y j 我们令暴露量:E j = 10 n j E_j=10n_j E j = 10 n j
E ( ω j ∣ y j ) = α + y j β + E j E(\omega_j\mid y_j) = \frac{\alpha+y_j}{\beta+E_j} E ( ω j ∣ y j ) = β + E j α + y j 我们可以改写:
α + y j β + E j = β β + E j α β + E j β + E j y j E j \frac{\alpha+y_j}{\beta+E_j} = \frac{\beta}{\beta+E_j}\frac{\alpha}{\beta} + \frac{E_j}{\beta+E_j}\frac{y_j}{E_j} β + E j α + y j = β + E j β β α + β + E j E j E j y j 我们可以发现:这个后验均值就是先验和数据的折衷:
后验均值 = 先验权重 * 先验均值 + 数据权重 * 死亡率
换句话说,当我们人口越小的县,那么其 E j E_j E j E j E_j E j
y j y_j y j
p ( y j ) = ∫ p ( y j ∣ ω j ) p ( ω j ) d ω j p(y_j) = \int p(y_j\mid \omega_j)p(\omega_j)\,d\omega_j p ( y j ) = ∫ p ( y j ∣ ω j ) p ( ω j ) d ω j 我们之前也说过,此时计算的结果是负二项分布:
P ( Y j = y ) = Γ ( α + y ) Γ ( α ) y ! ( β β + E j ) α ( E j β + E j ) y P(Y_j=y) = \frac{\Gamma(\alpha+y)}{\Gamma(\alpha)y!}
\left(\frac{\beta}{\beta+E_j}\right)^\alpha
\left(\frac{E_j}{\beta+E_j}\right)^y P ( Y j = y ) = Γ ( α ) y ! Γ ( α + y ) ( β + E j β ) α ( β + E j E j ) y 其中,均值和方差为:
E ( Y j ) = E j α β var ( Y j ) = E j α β + E j 2 α β 2 E(Y_j)=E_j\frac{\alpha}{\beta} \\
\operatorname{var}(Y_j) = E_j\frac{\alpha}{\beta} + E_j^2\frac{\alpha}{\beta^2} E ( Y j ) = E j β α var ( Y j ) = E j β α + E j 2 β 2 α 我们看回方差,我们可以知道其第一项来自 Poisson 抽样波动,第二项来自县与县之间死亡率 ω j \omega_j ω j
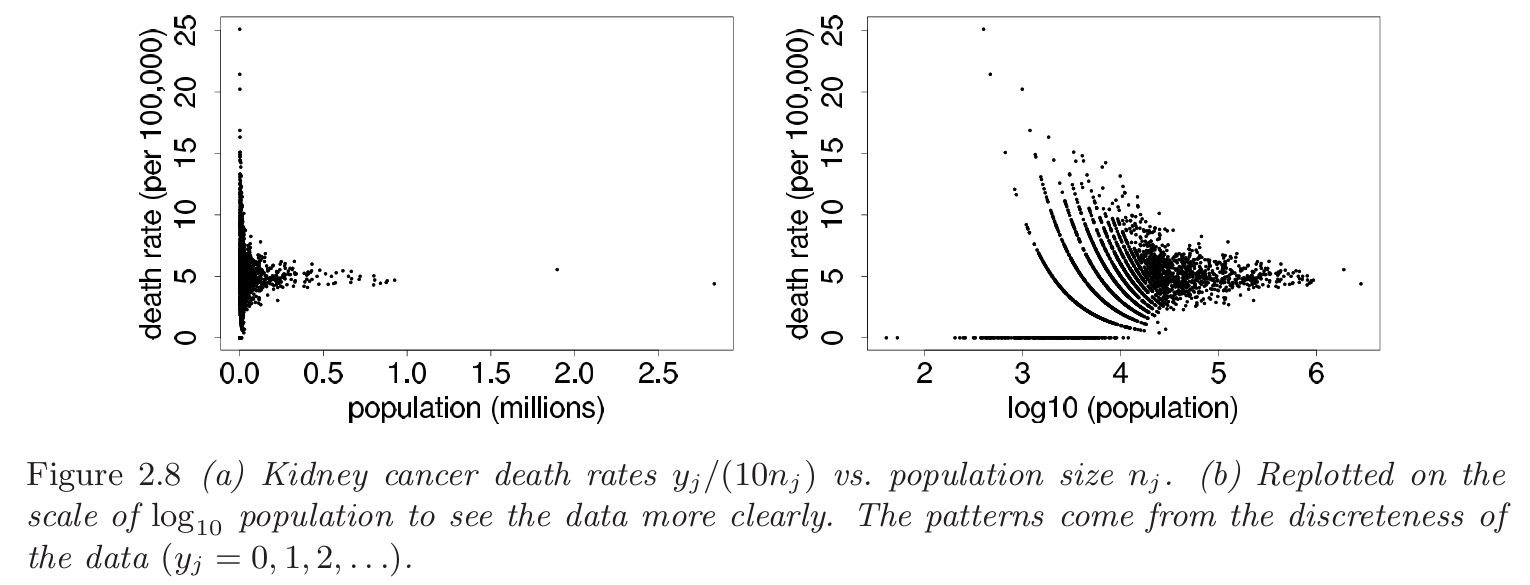
我们首先看真实情况:
我们可以清晰的看到人口小的县更容易出现极端死亡率。
我们假设一个人口数少的县,n=1,000
那么,十年的人年数为10,000:
如果,在这十年内没有人死亡,即y j = 0 y_j=0 y j = 0 0 0 0
20 430000 + 10000 = 20 440000 = 4.55 × 10 − 5 \frac{20}{430000+10000} = \frac{20}{440000} = 4.55\times 10^{-5} 430000 + 10000 20 = 440000 20 = 4.55 × 1 0 − 5 当 y j = 1 y_j=1 y j = 1 10 − 4 10^{-4} 1 0 − 4
21 440000 = 4.77 × 10 − 5 \frac{21}{440000} = 4.77\times 10^{-5} 440000 21 = 4.77 × 1 0 − 5 当 y j = 2 y_j=2 y j = 2
22 440000 = 5.00 × 10 − 5 \frac{22}{440000} = 5.00\times 10^{-5} 440000 22 = 5.00 × 1 0 − 5 对小县来说,0 例、1 例、2 例造成的死亡率差异非常大,但贝叶斯估计会收缩到总体先验均值 附近。这种收缩是在承认小样本条件下原始率噪声很大的基础上,把总体信息纳入估计。
如果 n j = 1000000 n_j=1000000 n j = 1000000 E j = 10 n j = 10000000 E_j=10n_j=10000000 E j = 10 n j = 10000000 [ 393 , 545 ] [393,545] [ 393 , 545 ]
假设,当 y j = 393 y_j=393 y j = 393 3.93 × 10 − 5 3.93\times 10^{-5} 3.93 × 1 0 − 5
20 + 393 430000 + 10000000 = 3.96 × 10 − 5 \frac{20+393}{430000+10000000} = 3.96\times 10^{-5} 430000 + 10000000 20 + 393 = 3.96 × 1 0 − 5 而当 y j = 545 y_j=545 y j = 545 5.45 × 10 − 5 5.45\times 10^{-5} 5.45 × 1 0 − 5
20 + 545 430000 + 10000000 = 5.41 × 10 − 5 \frac{20+545}{430000+10000000} = 5.41\times 10^{-5} 430000 + 10000000 20 + 545 = 5.41 × 1 0 − 5 对于大县来说,真实死亡率和后验均值非常接近,因为数据量已经足够大,先验的影响很小
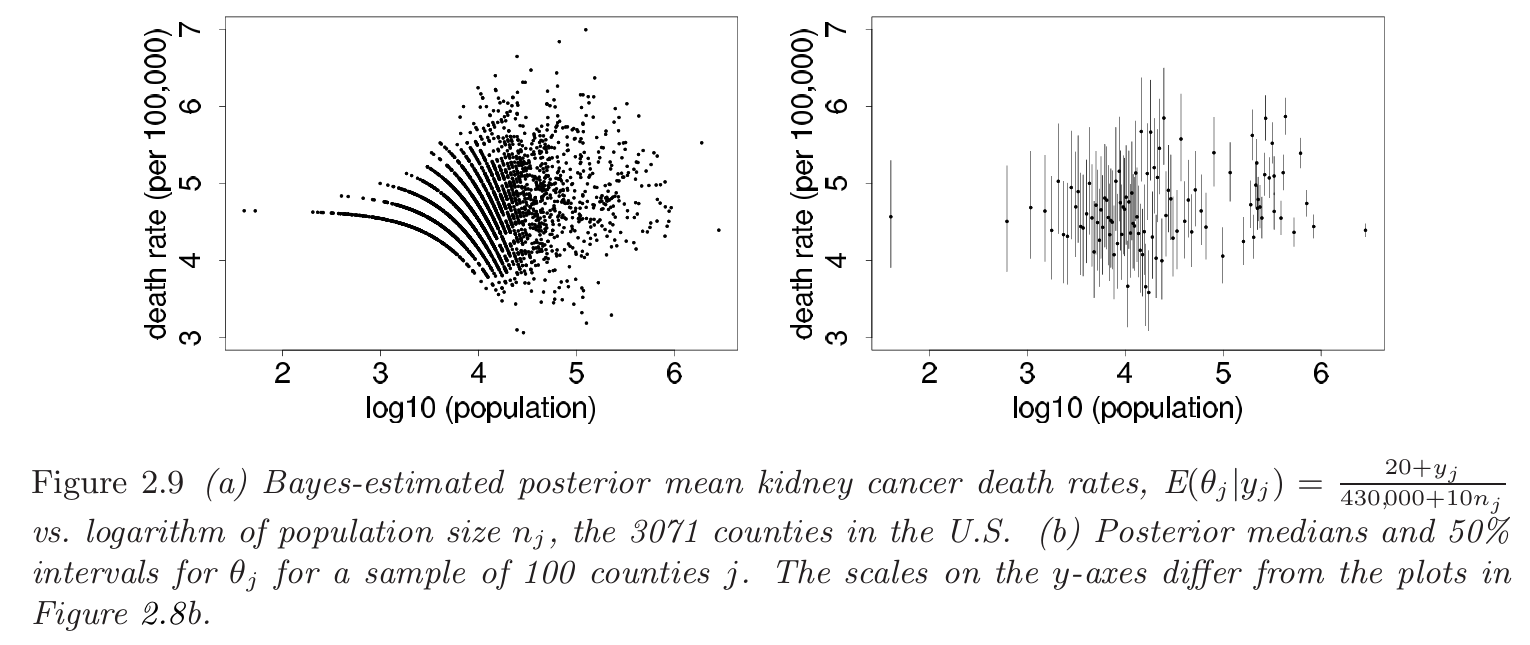
下面这幅图就很明显展示不同人口下其死亡率的估计,且随着人口数增大,其置信区间也会变小。
我们先计算可观测的死亡率:
R j = y j 10 n j R_j=\frac{y_j}{10n_j} R j = 10 n j y j 此时对于先验预测,我们计算其均值和方差为:
E ( R j ) = α β var ( R j ) = 1 10 n j α β + α β 2 E(R_j)=\frac{\alpha}{\beta} \\
\operatorname{var}(R_j) = \frac{1}{10n_j}\frac{\alpha}{\beta} + \frac{\alpha}{\beta^2} E ( R j ) = β α var ( R j ) = 10 n j 1 β α + β 2 α 由于不同县的 n j n_j n j 1 / ( 10 n j ) 1/(10n_j) 1/ ( 10 n j ) α , β \alpha,\beta α , β
其实是Proper prior和improper prior,更多的是它是否在后验收敛,为了减少犯错概率后面用英文代称。
如果一个先验密度 p ( θ ) p(\theta) p ( θ )
∫ p ( θ ) d θ = 1 \int p(\theta)\,d\theta=1 ∫ p ( θ ) d θ = 1 那么我们称作为proper prior。其实通常的,只要其是收敛于一个常数即可,当不收敛于1而收敛于其他常数时,我们称作非正态密度,但是其可以被标准化,通过乘以积分值倒数即可。而如果其不收敛:
∫ p ( θ ) d θ = ∞ \int p(\theta)\,d\theta=\infty ∫ p ( θ ) d θ = ∞ 则它是 improper prior。improper prior 不是合法的概率分布。但需要注意的是,我们仍然可以用improper prior得到proper posterior。因此二者并不是等价的。
我们看回已知方差的正态分布的例子:
y i ∣ θ ∼ N ( θ , σ 2 ) θ ∼ N ( μ 0 , τ 0 2 ) y_i\mid \theta \sim N(\theta,\sigma^2) \\
\theta\sim N(\mu_0,\tau_0^2) y i ∣ θ ∼ N ( θ , σ 2 ) θ ∼ N ( μ 0 , τ 0 2 ) 我们之前算过,此时后验的precision为:
1 τ 0 2 + n σ 2 \frac{1}{\tau_0^2}+\frac{n}{\sigma^2} τ 0 2 1 + σ 2 n 我们知道,当先验的precision远小于数据本身的precision时,我们会有:
p ( θ ∣ y ) ≈ N ( y ˉ , σ 2 n ) p(\theta\mid y)\approx N\left(\bar y,\frac{\sigma^2}{n}\right) p ( θ ∣ y ) ≈ N ( y ˉ , n σ 2 ) 此时,我们等价于将先验里的 τ 0 2 → ∞ \tau_0^2 \to \infin τ 0 2 → ∞ p ( θ ) ∝ 1 , − ∞ < θ < ∞ p(\theta)\propto 1,\qquad -\infty<\theta<\infty p ( θ ) ∝ 1 , − ∞ < θ < ∞
那么显然,∫ p ( θ ) d θ = ∞ \int p(\theta)\,d\theta=\infty ∫ p ( θ ) d θ = ∞ n > 0 n > 0 n > 0
因此,既然improper prior可以算出proper posterior,那么prior的设定是否proper好像就不重要了,但事实情况是,我们要明白我们的目的是获得未知参数 θ \theta θ
∫ p ( y ∣ θ ) p ( θ ) d θ < ∞ \int p(y\mid \theta)p(\theta)\,d\theta < \infty ∫ p ( y ∣ θ ) p ( θ ) d θ < ∞ 如果这个积分有限,就可以把未归一化后验归一化为 proper posterior;如果积分无限,后验本身就不是概率分布,那么后续的推断就没有意义。
在选择非信息先验的时候,我们首先要知道我们选择的分布,参数都是人为选择的,这种情况下会引入主观性,因此Jeffreys提出了解决方案:首先我们在这里先借用一个分布,即二项分布,以二项分布中的成功概率为例,参数可以直接写成:θ ∈ ( 0 , 1 ) \theta\in(0,1) θ ∈ ( 0 , 1 )
ϕ = logit ( θ ) = log θ 1 − θ , θ = e ϕ 1 + e ϕ \phi=\operatorname{logit}(\theta) =\log\frac{\theta}{1-\theta},
\qquad
\theta=\frac{e^\phi}{1+e^\phi} ϕ = logit ( θ ) = log 1 − θ θ , θ = 1 + e ϕ e ϕ 此时,θ \theta θ ϕ \phi ϕ θ \theta θ ϕ = h ( θ ) \phi=h(\theta) ϕ = h ( θ ) 等价 的先验密度。
我们用一个例子来看:
在均匀先验下:p θ ( θ ) = 1 , 0 < θ < 1 p_\theta(\theta)=1,\qquad 0<\theta<1 p θ ( θ ) = 1 , 0 < θ < 1
若令:ϕ = logit ( θ ) \phi=\operatorname{logit}(\theta) ϕ = logit ( θ )
则:
d θ d ϕ = e ϕ ( 1 + e ϕ ) − e ϕ ⋅ e ϕ ( 1 + e ϕ ) 2 = e ϕ ( 1 + e ϕ ) 2 = θ 1 − θ ( 1 + θ 1 − θ ) 2 = θ ( 1 − θ ) \begin{aligned}
\frac{d\theta}{d\phi} &= \frac{e^{\phi}(1+e^{\phi})-e^{\phi}\cdot e^{\phi}}{(1+e^{\phi})^2} \\
&= \frac{e^{\phi}}{(1+e^{\phi})^2} \\
&= \frac{{\frac{\theta}{1-\theta}}}{(1+\frac{\theta}{1-\theta})^2} \\
&= \theta(1-\theta)
\end{aligned} d ϕ d θ = ( 1 + e ϕ ) 2 e ϕ ( 1 + e ϕ ) − e ϕ ⋅ e ϕ = ( 1 + e ϕ ) 2 e ϕ = ( 1 + 1 − θ θ ) 2 1 − θ θ = θ ( 1 − θ ) 根据密度变换公式(一维Jacobian):
p ϕ ( ϕ ) = p θ ( θ ) ∣ d θ d ϕ ∣ p_\phi(\phi)=p_\theta(\theta)\left|\frac{d\theta}{d\phi}\right| p ϕ ( ϕ ) = p θ ( θ ) d ϕ d θ 因此:
p ϕ ( ϕ ) = θ ( 1 − θ ) = e ϕ ( 1 + e ϕ ) 2 p_\phi(\phi) = \theta(1-\theta) = \frac{e^\phi}{(1+e^\phi)^2} p ϕ ( ϕ ) = θ ( 1 − θ ) = ( 1 + e ϕ ) 2 e ϕ 这个密度在 ϕ \phi ϕ ϕ \phi ϕ
假设我们在 logit 尺度上取均匀先验:p ϕ ( ϕ ) ∝ 1 p_\phi(\phi)\propto 1 p ϕ ( ϕ ) ∝ 1
则变换回概率尺度有
p θ ( θ ) = p ϕ ( ϕ ) ∣ d ϕ d θ ∣ ∝ 1 θ ( 1 − θ ) p_\theta(\theta)=p_\phi(\phi)\left|\frac{d\phi}{d\theta}\right|\propto\frac{1}{\theta(1-\theta)} p θ ( θ ) = p ϕ ( ϕ ) d θ d ϕ ∝ θ ( 1 − θ ) 1 这对应 improper 的 Beta ( 0 , 0 ) \operatorname{Beta}(0,0) Beta ( 0 , 0 ) θ \theta θ Beta ( 1 , 1 ) \operatorname{Beta}(1,1) Beta ( 1 , 1 )
给定似然:p ( y ∣ θ ) p(y\mid \theta) p ( y ∣ θ ) ℓ ( θ ) = log p ( y ∣ θ ) \ell(\theta)=\log p(y\mid \theta) ℓ ( θ ) = log p ( y ∣ θ )
参数 θ \theta θ
J ( θ ) = E [ ( ∂ ℓ ( θ ) ∂ θ ) 2 | θ ] = − E [ ∂ 2 ℓ ( θ ) ∂ θ 2 | θ ] J(\theta) =
E\left[\left(\frac{\partial \ell(\theta)}{\partial \theta}\right)^2\middle|\theta\right]=-
E\left[\frac{\partial^2 \ell(\theta)}{\partial \theta^2}\middle|\theta\right] J ( θ ) = E [ ( ∂ θ ∂ ℓ ( θ ) ) 2 θ ] = − E [ ∂ θ 2 ∂ 2 ℓ ( θ ) θ ] 则Jeffreys 先验定义为;
p J ( θ ) ∝ J ( θ ) p_J(\theta)\propto \sqrt{J(\theta)} p J ( θ ) ∝ J ( θ ) J ( θ ) J(\theta) J ( θ ) θ \theta θ J ( θ ) \sqrt{J(\theta)} J ( θ ) 某些模型中的 Jeffreys 先验仍然是 improper prior,仍需检查后验密度是否收敛 。
书上的主要内容如上,但我觉得对于我而言这是一个比较难以理解的知识点
接下来我们进行一个证明:
设参数的一一变换为 ϕ = h ( θ ) , θ = h − 1 ( ϕ ) \phi=h(\theta),\quad\ \theta=h^{-1}(\phi) ϕ = h ( θ ) , θ = h − 1 ( ϕ )
我们对似然进行对数转化,则有:
ℓ ( ϕ ) = log p ( y ∣ ϕ ) = log p ( y ∣ θ = h − 1 ( ϕ ) ) = ℓ ( θ ) \ell(\phi)=\log p(y\mid \phi)=\log p(y\mid \theta=h^{-1}(\phi))=\ell(\theta) ℓ ( ϕ ) = log p ( y ∣ ϕ ) = log p ( y ∣ θ = h − 1 ( ϕ )) = ℓ ( θ ) 由链式法则:
∂ ℓ ( ϕ ) ∂ ϕ = ∂ ℓ ( θ ) ∂ θ d θ d ϕ \frac{\partial \ell(\phi)}{\partial \phi} =
\frac{\partial \ell(\theta)}{\partial \theta}
\frac{d\theta}{d\phi} ∂ ϕ ∂ ℓ ( ϕ ) = ∂ θ ∂ ℓ ( θ ) d ϕ d θ 两边平方并取期望:
J ϕ ( ϕ ) = E [ ( ∂ ℓ ( ϕ ) ∂ ϕ ) 2 | ϕ ] = E [ ( ∂ ℓ ( θ ) ∂ θ ) 2 | θ ] ∣ d θ d ϕ ∣ 2 J_\phi(\phi) =
E\left[ \left( \frac{\partial \ell(\phi)}{\partial \phi} \right)^2 \middle|\phi \right] =
E\left[ \left( \frac{\partial \ell(\theta)}{\partial \theta} \right)^2 \middle|\theta \right] \left| \frac{d\theta}{d\phi} \right|^2 J ϕ ( ϕ ) = E [ ( ∂ ϕ ∂ ℓ ( ϕ ) ) 2 ϕ ] = E [ ( ∂ θ ∂ ℓ ( θ ) ) 2 θ ] d ϕ d θ 2 即:
J ϕ ( ϕ ) = J θ ( θ ) ∣ d θ d ϕ ∣ 2 ⇒ J ϕ ( ϕ ) = J θ ( θ ) ∣ d θ d ϕ ∣ J_\phi(\phi)=J_\theta(\theta)\left|\frac{d\theta}{d\phi}\right|^2
\\ \Rightarrow \sqrt{J_\phi(\phi)} = \sqrt{J_\theta(\theta)} \left| \frac{d\theta}{d\phi} \right| J ϕ ( ϕ ) = J θ ( θ ) d ϕ d θ 2 ⇒ J ϕ ( ϕ ) = J θ ( θ ) d ϕ d θ 另一方面,密度变换公式为:
p ϕ ( ϕ ) = p θ ( θ ) ∣ d θ d ϕ ∣ p_\phi(\phi) = p_\theta(\theta) \left| \frac{d\theta}{d\phi} \right| p ϕ ( ϕ ) = p θ ( θ ) d ϕ d θ 若在 θ \theta θ
p θ ( θ ) ∝ J θ ( θ ) p_\theta(\theta)\propto \sqrt{J_\theta(\theta)} p θ ( θ ) ∝ J θ ( θ ) 当变换到 ϕ \phi ϕ
p ϕ ( ϕ ) ∝ J θ ( θ ) ∣ d θ d ϕ ∣ = J ϕ ( ϕ ) p_\phi(\phi) \propto \sqrt{J_\theta(\theta)} \left| \frac{d\theta}{d\phi} \right| = \sqrt{J_\phi(\phi)} p ϕ ( ϕ ) ∝ J θ ( θ ) d ϕ d θ = J ϕ ( ϕ ) 依旧我们使用二项分布来为我们的例子:
y ∼ Bin ( n , θ ) y\sim \operatorname{Bin}(n,\theta) y ∼ Bin ( n , θ ) 则似然为:
p ( y ∣ θ ) = ( n y ) θ y ( 1 − θ ) n − y p(y\mid \theta) = \binom{n}{y}\theta^y(1-\theta)^{n-y} p ( y ∣ θ ) = ( y n ) θ y ( 1 − θ ) n − y 取对数:
ℓ ( θ ) = constant + y log θ + ( n − y ) log ( 1 − θ ) \ell(\theta)=\text{constant}+y\log\theta+(n-y)\log(1-\theta) ℓ ( θ ) = constant + y log θ + ( n − y ) log ( 1 − θ ) 计算对数似然的二阶导数:
∂ 2 ℓ ( θ ) ∂ θ 2 = − y θ 2 − n − y ( 1 − θ ) 2 \frac{\partial^2 \ell(\theta)}{\partial \theta^2} = - \frac{y}{\theta^2} - \frac{n-y}{(1-\theta)^2} ∂ θ 2 ∂ 2 ℓ ( θ ) = − θ 2 y − ( 1 − θ ) 2 n − y 于是乎,计算Fisher信息:
J ( θ ) = − E [ ∂ 2 ℓ ( θ ) ∂ θ 2 | θ ] = − E [ − y θ 2 − n − y ( 1 − θ ) 2 | θ ] = E [ y ∣ θ ] θ 2 + E [ n − y ∣ θ ] ( 1 − θ ) 2 = n θ θ 2 + n ( 1 − θ ) ( 1 − θ ) 2 = n θ + n 1 − θ = n θ ( 1 − θ ) \begin{aligned}
J(\theta)&=-E\left[\frac{\partial^2 \ell(\theta)}{\partial \theta^2}\middle|\theta\right] \\
&= -E\left[- \frac{y}{\theta^2} - \frac{n-y}{(1-\theta)^2} \middle| \theta \right] \\
&= \frac{E[y|\theta]}{\theta^2} + \frac{E[n-y|\theta]}{(1-\theta)^2}\\
&=\frac{n\theta}{\theta^2}+\frac{n(1-\theta)}{(1-\theta)^2} \\
&=\frac{n}{\theta}+\frac{n}{1-\theta} \\
&=\frac{n}{\theta(1-\theta)}
\end{aligned} J ( θ ) = − E [ ∂ θ 2 ∂ 2 ℓ ( θ ) θ ] = − E [ − θ 2 y − ( 1 − θ ) 2 n − y θ ] = θ 2 E [ y ∣ θ ] + ( 1 − θ ) 2 E [ n − y ∣ θ ] = θ 2 n θ + ( 1 − θ ) 2 n ( 1 − θ ) = θ n + 1 − θ n = θ ( 1 − θ ) n 因此Jeffreys 先验为:
p J ( θ ) ∝ n θ ( 1 − θ ) p_J(\theta)\propto \sqrt{\frac{n}{\theta(1-\theta)}} p J ( θ ) ∝ θ ( 1 − θ ) n 由于 n n n θ \theta θ
p J ( θ ) ∝ θ − 1 / 2 ( 1 − θ ) − 1 / 2 p_J(\theta)\propto\theta^{-1/2}(1-\theta)^{-1/2} p J ( θ ) ∝ θ − 1/2 ( 1 − θ ) − 1/2 所以我们构造的先验为:
θ ∼ Beta ( 1 2 , 1 2 ) \theta\sim \operatorname{Beta}\left(\frac12,\frac12\right) θ ∼ Beta ( 2 1 , 2 1 ) 所以后验为:
p ( θ ∣ y ) ∝ p ( y ∣ θ ) p J ( θ ) ∝ θ y ( 1 − θ ) n − y θ − 1 / 2 ( 1 − θ ) − 1 / 2 = θ y − 1 / 2 ( 1 − θ ) n − y − 1 / 2 . \begin{aligned}
p(\theta\mid y)
&\propto
p(y\mid \theta)p_J(\theta) \\
&\propto
\theta^y(1-\theta)^{n-y}
\theta^{-1/2}(1-\theta)^{-1/2} \\
&=
\theta^{y-1/2}(1-\theta)^{n-y-1/2}.
\end{aligned} p ( θ ∣ y ) ∝ p ( y ∣ θ ) p J ( θ ) ∝ θ y ( 1 − θ ) n − y θ − 1/2 ( 1 − θ ) − 1/2 = θ y − 1/2 ( 1 − θ ) n − y − 1/2 . 仍然为Beta分布,θ ∣ y ∼ Beta ( y + 1 2 , n − y + 1 2 ) \theta\mid y\sim \operatorname{Beta}\left(y+\frac12,n-y+\frac12\right) θ ∣ y ∼ Beta ( y + 2 1 , n − y + 2 1 ) α > 0 , β > 0 \alpha>0, \quad \beta>0 α > 0 , β > 0
定义:设总体 X X X f ( x ; θ ) f(x;\theta) f ( x ; θ ) θ \theta θ X 1 , … , X n X_1,\dots,X_n X 1 , … , X n
G = G ( X 1 , … , X n ; θ ) G = G(X_1,\dots,X_n;\theta) G = G ( X 1 , … , X n ; θ ) 为样本和待估参数 θ \theta θ G G G G G G
也就是说,枢轴量与某个待估参数有关(其主要用于未知参数的区间估计 ),且本身含有未知参数(待估参数),因此具有“不可观察性 ”,也就是说即使选定了样本也无法计算出确定的值;其分布是明确的(有具体的数学公式,不包含未知参数)
例如:若有 y ∣ θ ∼ N ( θ , σ 2 ) y\mid \theta\sim N(\theta,\sigma^2) y ∣ θ ∼ N ( θ , σ 2 ) σ 2 \sigma^2 σ 2 u = y − θ u=y-\theta u = y − θ θ \theta θ u ∣ θ = y − θ ∼ N ( 0 , σ 2 ) u\mid \theta=y-\theta\sim N(0,\sigma^2) u ∣ θ = y − θ ∼ N ( 0 , σ 2 ) u u u θ \theta θ u = y − θ u=y-\theta u = y − θ
枢轴量意义在于:把数据相对于参数的偏离标准化成一个分布已知的量。在构造非信息先验时,可以要求在观察到数据后,这个枢轴量的后验分布仍然保持其原来的抽样分布。这个要求的成立假设为:在缺少额外先验信息时,数据只改变参数的位置或尺度 ,不额外改变枢轴量本身的分布形状。
对于位置参数,参数只控制分布的平移。并且在没有额外信息时,一个自然的做法是在位置尺度上不给任何位置更多权重,因此得到:
p ( θ ) ∝ 1 p(\theta)\propto 1 p ( θ ) ∝ 1 对于尺度参数,参数控制分布的伸缩。在没有额外信息时,一个自然做法是对乘法尺度上的相对变化给相同权重,也就是在 log θ \log\theta log θ
p ( θ ) ∝ 1 θ p(\theta)\propto \frac{1}{\theta} p ( θ ) ∝ θ 1 枢轴量在构造非信息先验的适用范围有限。它适合纯位置参数 和纯尺度参数 这类结构清楚的单参数模型 。对于多参数模型、分层模型或参数之间相互耦合的模型,枢轴量可能不唯一 ,依据不同枢轴量得到的先验也可能不同。
如果数据真的足够强,那么在一组相对平坦的先验之间,不论哪一个选择通常不会显著影响后验
平坦性依赖参数化。一个在 θ \theta θ log θ \log\theta log θ θ 2 \theta^2 θ 2
improper prior 在模型比较或模型平均中会造成额外困难,因为不同模型中的归一化常数可能没有定义
弱信息先验是 proper prior,其放入了少量的信息,它的目的是提供足够约束,使后验不会跑到明显不合理的区域。因为在很多实际问题中,我们并不是对先验分布一无所知,即便不能精确写出完整的先验分布,也通常知道参数不可能离谱到某些程度。
也就是说,弱信息先验是介于强信息先验和非信息先验的居中,我们举个例子:
对于性别而言,我们不知道这真正的比例,但我们知道这个比例不太可能远离0.5, 因此此时可以使用集中在 0.4 到 0.6 附近的先验(或者更加严格),例如:N ( 0.5 , 0.1 2 ) N(0.5,0.1^2) N ( 0.5 , 0. 1 2 ) [ 0 , 1 ] [0,1] [ 0 , 1 ] θ ∼ Beta ( 20 , 20 ) \theta\sim \operatorname{Beta}(20,20) θ ∼ Beta ( 20 , 20 ) 80% 的概率会落在0.4-0.6. 这个先验很松,但其排除了明显不合理的范围。
在构造弱信息先验时,我们主要可以从两点出发:
从非信息先验出发,通过加上一点先验信息,使得推断在合理范围以内。比如估计罕见病患病率,我们不能使用一个 θ ∼ U ( 0 , 1 ) \theta\sim U(0,1) θ ∼ U ( 0 , 1 ) θ ∣ y ∼ Beta ( 1 , 101 ) \theta\mid y\sim \operatorname{Beta}(1,101) θ ∣ y ∼ Beta ( 1 , 101 )
从强信息先验出发,把它适当放宽,以反映历史信息和当前研究场景之间可能存在的差异。比如历史数据可能强烈提示某个治疗效应为正,但当前实验面对的人群、剂量、测量方式可能不同。我们可以保留效应大致为正的信息,但扩大先验方差,避免历史信息过度支配新数据。
在有些场景下,即使我们想要的确实是方向性先验,也可能不希望把它直接放进分析中。比如假设我们相信某个处理效应为正,但实验本身是为了检验这个理论。如果直接使用偏向正效应的先验,就会降低证据门槛。在这种情况下,我们可以使用关于 0 对称的弱信息先验,如 θ ∼ N ( 0 , A 2 ) \theta\sim N(0,A^2) θ ∼ N ( 0 , A 2 )
类型
目标
典型特点
主要风险
有信息先验
尽量表达已有科学知识或总体信息
可能明显影响小样本后验
若先验来源不适用,会引入偏差
非信息先验
尽量减少先验影响
常常很平坦,甚至 improper
参数化依赖、后验可能 improper
弱信息先验
只排除明显不合理区域,起到正则化作用
proper,较宽,但有实际尺度
若尺度选得不当,可能仍太强或太弱