
笔记
因果推断(13)——双重差分与双向固定效应
DID与TWFE
回顾
我们之前提到了双重差分,其常可以用于评估政策或者某个处理实施后的效果。我们也知道,可以使用面板数据对同一单位在多个时间段进行重复观测。DID关心的通常不是每一个个体的个体化效应,而是某一类被处理单位在处理后的平均效应。
先把最核心的符号写清楚。设 表示单位 在时间 接受处理时的潜在结果, 表示没有接受处理时的潜在结果。我们真正想知道的是被处理单位在处理后如果没有处理会怎样,也就是反事实 。对已经被处理的单位而言, 能观察到,但 不能观察到。
最简单的二期二组DID中,处理组为 ,对照组为 ,处理发生在 的时期。平行趋势假设可以写成:
它的意思不是处理组和对照组的水平一样,而是如果没有处理,两组的变化趋势一样。有了这个假设,我们才可以用对照组的变化来推断处理组在没有处理时本该发生的变化。
二期二组的DID估计量可以写成:
也可以通过回归写成:
其中 就是DID估计量。这个例子中,DID是研究设计,而回归只是实现这个设计的一种估计方法。
分析例子
为了理解TWFE的问题,我们先用一个贯穿例子。假设一个应用上线了一个新功能,但不是所有用户同一天看到这个功能 (这很自然):
- 第一批用户在
2025-06-01收到新功能; - 第二批用户在
2025-07-15收到新功能; - 还有一批用户在我们的观察窗口内一直没有收到新功能,可以作为从未处理组;
- 结果变量 是用户每天的活跃时长、安装量、购买次数等。
这个例子有两个现实特征。第一,处理时间是错开的,不同 cohort 的 不同。第二,处理效应不是瞬间达到最大,而是会随着处理后的天数逐渐成熟。比如新功能上线后,用户可能需要几天才会发现、学习并稳定使用它。
我们用 表示单位 的首次处理时间。如果单位从未处理,可以记为 。处理状态为:
在错位处理时间中,潜在结果记号也要更细一些。令 表示单位 如果在时期 首次接受处理,那么它在时期 的潜在结果;令 表示单位 在观察窗口内始终没有被处理时的潜在结果。若处理一旦发生后持续存在,则实际观测结果为 。
对一个在时间 开始处理的 cohort,我们在时间 的目标效应是:
这里的 很重要,它提醒我们:在错位处理时间中,处理效应天然可以随 cohort 和时间变化。因此,更常见的写法是用相对处理时间 :
如果新功能需要一段时间才生效,那么可能有:
这就是后面TWFE出现偏误的关键。但在这里,我们先不详细分析
双向固定效应(Two-way Fixed Effects)
通常而言,假设在某个时间点 ,我们想知道处理对结果的影响。一个直觉想法是:如果我们知道被处理单位在没有处理时的结果就好了。于是,我们要估计:
问题是 不能直接观察到。DID的做法是用合适的对照组来构造这个反事实。而TWFE则是最常见的回归实现:
其中:
- 是单位固定效应,用来吸收单位之间不随时间变化的差异;
- 是时间固定效应,用来吸收所有单位共同经历的时间冲击;
- 是处理状态;
- 是TWFE给出的平均处理效应估计。
这时候要注意一个概念区分:DID是一种研究设计,TWFE是一种估计器。DID说的是如何利用处理组和对照组在处理前后的变化构造反事实;TWFE说的是如何用含单位固定效应和时间固定效应的线性回归去估计这个反事实。二期二组时,TWFE和DID完全一致;但在多期、错位处理时间、处理效应异质时,TWFE不一定还能估计我们想要的DID目标量。
从Frisch-Waugh-Lovell theorem的角度看(我们之前反复提过这个定理),TWFE的 来自先把 和 中能被单位固定效应、时间固定效应解释的部分拿掉,再用剩下的处理变化解释剩下的结果变化。记残差化后的变量为 和 ,则:
更完整的双向去均值形式是:
因此TWFE估计量可以写成:
这个写法很有用,因为它告诉我们TWFE真正使用的是 中不能被“单位是谁”和“今天是哪一天”解释的那部分变化。
TWFE偏误
先写出一个带潜在结果的模型。假设观察到的结果为:
其中 是单位 在时间 的真实处理效应。如果没有处理时的结果满足:
当平行趋势等外生条件成立,那么TWFE的主要问题不在 ,而在它如何平均不同的 。设 是将 对单位固定效应和时间固定效应回归后的残差。在未处理潜在结果满足 的理想情形下,TWFE系数可以写成:
其中权重为:
这里第二个等号利用了二元处理变量和残差正交性质。这些权重的和为 ,但它们不一定都是正的。问题就在这里:如果处理效应完全同质,即 ,那么无论权重怎么分配,TWFE都会回到同一个 。但如果处理效应随 cohort 或相对处理时间变化,那么TWFE就可能把一些真实效应用负权重计入,最后得到一个难以解释的加权平均。
上面的简单双向去均值写法适合平衡面板和未加权回归。若数据是非平衡面板、使用了回归权重或有复杂抽样权重,就应当把 理解为相应固定效应回归设定下的残差,而不能机械套用简单的双向去均值公式。
因此,TWFE的关键缺陷是:
- 它把所有 cohort、所有处理后时期压缩成一个共同的 ;
- 它在错位处理时间下会把已经处理的单位拿来当其他单位的对照;
- 当处理效应随时间变化时,这些对照关系会混淆反事实趋势;
- 最终估计量除了理想状态下,其不是一个自然的、非负权重的ATT平均。
时间上的处理效应异质性
很多处理并不是一下子就能影响结果,而是有一个生效和成熟过程。比如应用新功能上线后,用户并不会立刻全部开始使用;医生收入改革也可能先改变奖金结构,再逐步改变工作行为和收入水平。换句话说,处理效应可以是动态的:
若效应只取决于处理后的时间长度,可以写成:
例如一个逐渐成熟的效应可以写成:
这表示处理后第0天几乎没有效果,之后每天增加 ,直到最大效果为 。在这种情况下,早处理 cohort 在较晚日期已经积累了较大的处理效应,而晚处理 cohort 刚开始处理时效应还比较小。
我们模拟一组数据:
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
date = pd.date_range("2025-05-01", "2025-07-31", freq="D")
cohorts = pd.to_datetime(["2025-06-01", "2025-07-15", "2026-01-01"])
units = range(1, 100+1)
np.random.seed(1)
df_heter = pd.DataFrame(dict(
date = np.tile(date, len(units)),
unit = np.repeat(units, len(date)),
cohort = np.repeat(np.random.choice(cohorts, len(units)), len(date)),
unit_fe = np.repeat(np.random.normal(0, 5, size=len(units)), len(date)),
time_fe = np.tile(np.random.normal(size=len(date)), len(units)),
week_day = np.tile(date.weekday, len(units)),
w_seas = np.tile(abs(5-date.weekday) % 7, len(units)),
)).assign(
trend = lambda d: (d["date"] - d["date"].min()).dt.days / 70,
day = lambda d: (d["date"] - d["date"].min()).dt.days,
treat = lambda d: (d["date"] >= d["cohort"]).astype(int),
).assign(
y0 = lambda d: 10 + d["trend"] + 0.2 * d["unit_fe"] + 0.05 * d["time_fe"] + d["w_seas"] / 50,
).assign(
y1 = lambda d: d["y0"] + np.minimum(0.1 * (np.maximum(0, (d["date"] - d["cohort"]).dt.days)), 1)
).assign(
tau = lambda d: d["y1"] - d["y0"],
effect = lambda d: np.where(d["treat"] == 1, d["y1"], d["y0"])
)
plt.figure(figsize=(10,4))
[plt.vlines(x=cohort, ymin=9, ymax=15, color=color, ls="dashed") for color, cohort in zip(["C0", "C1"], cohorts)]
sns.lineplot(
data=(df_heter
.groupby(["cohort", "date"])["effect"]
.mean()
.reset_index()),
x="date",
y = "effect",
hue="cohort",
)
plt.show()
可以看到有两组处理时间不一致:
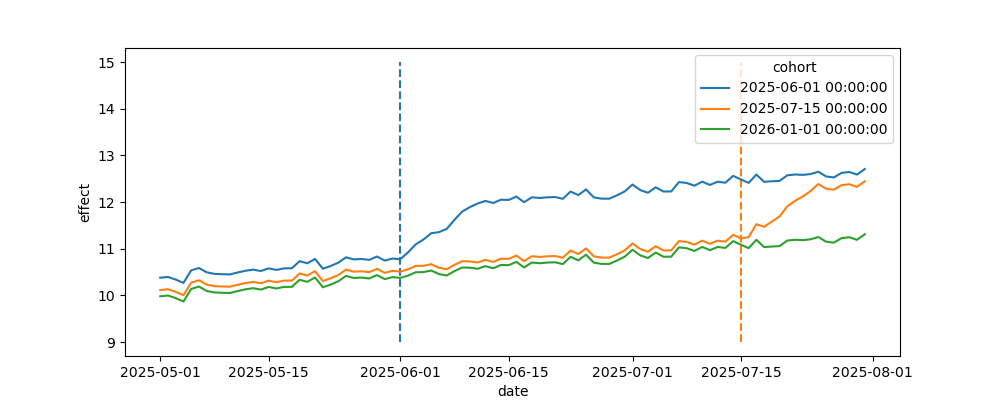
图中还可以看到,从处理开始到达到最终水平有一个平缓上升过程。这个过程会让TWFE出现偏误,因为TWFE会把错位处理时间拆成一系列 DID 比较。
在有两批处理组和一批从未处理组时,TWFE可以理解为下面几个比较的加权平均:
其中:
- 表示早处理组;
- 表示晚处理组;
- 表示从未处理组;
- 表示各个 DID 的权重。
这里要区分两个层面的“权重”。在 Goodman-Bacon 分解中,TWFE 估计量收敛于
且TWFE可以分解为若干个 DID 的加权平均,这些 比较层面的权重通常是非负且和为 。问题不一定是这些分解权重本身为负,而是某些 比较使用了已经处理的组作为对照。当处理效应随暴露时间变化时,这些比较本身就不再对应干净的因果效应。
前三个比较比较好理解:
- 早处理组 vs 从未处理组;
- 晚处理组 vs 从未处理组;
- 早处理组 vs 晚处理组尚未处理的时期。
真正重要的的是第四个比较:
它把晚处理组已经处理后的变化,与早处理组在同一时期的变化作比较。但此时早处理组早已接受处理,不能再被当成纯粹的对照组。如果早处理组的处理效应仍在持续增加,那么它的结果变化会包含“处理效应继续成熟”的部分。TWFE会把这部分变化误认为是晚处理组的反事实趋势,从而把晚处理组的处理效应压低。
这就是“已经处理组作为对照组”的问题。即使平行趋势、无预期等假设在未处理潜在结果上都成立,只要处理效应随时间变化,TWFE也可能有偏。上面的残差化权重公式说明了同一件事:当某些处理后观测的 时,它们会以负权重进入TWFE估计量。
更简洁地说:
其中: (#{(g,t):t\ge g}) 是计数函数,代表着所有已经接受处理的 单元数量。
TWFE估计的是一个由回归残差化机制决定的加权平均,而不是我们通常想要的、对 cohort-time ATT 的自然平均。
事件研究模型局限性
一个自然想法是:既然效应随相对处理时间变化,那么我们加入相对处理时间虚拟变量即可。例如:
这里 是相对处理时间, 通常被设为参考期。 的系数常被称为 lead,用来检查处理前是否存在预趋势; 的系数常被称为 lag,用来描述处理后的动态效应。
这个模型比单一TWFE更灵活,但在错位处理时间且处理效应异质时,它仍然可能被混淆。原因是:某一个 的对照组不一定是“从未处理或尚未处理”的干净单位,它仍然可能混入已经处理且处在其他相对时间的单位。
所以,问题不只是“有没有相对时间虚拟变量”,而是每一个相对时间效应到底是用哪些单位作为对照识别出来的。
使用 cohort-time ATT 估计异质效应
这类方法解决的是TWFE将异质处理效应用不透明权重混合的问题;它并不能替代平行趋势、无预期和无溢出等识别假设。
如果问题在于TWFE强迫所有时间、所有单位共享同一个处理效应:
那么一个自然修正是允许处理效应随 cohort 和时间变化。最细的写法是:
这等价于给每个“单位 时间”的处理状态都估计一个独立效应:
effect ~ treat:C(unit):C(date) + C(unit) + C(date)
但这个模型几乎没有实际意义,因为它会产生接近 个处理效应参数。我们不可能在每个单位、每个日期上都稳定估计一个独立因果效应。
更合理的做法是把单位按照首次处理时间 分组,并估计 cohort-time ATT:
这里可能会引起一些疑惑的点在于没有写出 ,其是因为求和已经限制在 的处理后时期。也就是说,当某个观测属于 且当前时间 时, 已经被隐含在这个限制里。等价地,上式也可以写成显式包含处理状态的三交互形式:
effect ~ treat:C(cohort):C(date) + C(unit) + C(date)
这里的三交互是为了回答一个明确的问题:
对于在 cohort 接受处理的单位,它们在时间 的处理效应是多少?
在识别假设成立时,每一个 都可以对应一个具体的 cohort-time ATT,而不是把所有处理后时期加权平均成一个共同 。如果对照组选择不干净,或者平行趋势、无预期、无溢出等假设不成立,那么这些系数只是饱和回归中的条件均值差异,不能直接解释为因果效应。
不过,直接用 C(date) 会把处理前日期也放进交互项。若我们接受“无预期效应”假设,即处理前的真实效应为0:
那么可以只对处理后时期估计参数:
这里 是相对处理时间。这个版本的好处是解释更自然: 是 cohort 刚接受处理时的效应, 是处理后第1期的效应,以此类推。同样的,这里也没有显示出 。
三交互项
用上面的应用新功能例子说明。假设我们有两个真实处理 cohort:
- ;
- 。
我们可以手动构造:
再构造相对处理时间:
三交互项:
只会在以下三个条件同时满足时取1:
- 单位属于 cohort ;
- 该单位在时间 已经被处理;
- 该观察值处于处理后第 期。
因此,对应系数 可以被解释为 cohort 在相对时间 的 ATT:
这个解释需要几个前提:对照组只来自从未处理或在该时期尚未处理的单位;无预期效应成立;cohort 与相应对照组的未处理潜在结果满足平行趋势;每个 都有足够的有效对照和样本重叠。否则,这些系数只是一个饱和回归中的条件均值差异,不应直接称为因果 ATT。
在这些条件成立时,它比单一TWFE的 清楚得多。它允许不同 cohort 有不同效应,也允许同一 cohort 的效应随处理后时间变化。
在代码中,可以直接构造相对处理时间来近似:
import statsmodels.formula.api as smf
def feature_eng_event(df):
out = df.assign(
rel_day=lambda d: (d["date"] - d["cohort"]).dt.days,
cohort_0601=lambda d: d["cohort"].eq(pd.Timestamp("2025-06-01")).astype(int),
cohort_0715=lambda d: d["cohort"].eq(pd.Timestamp("2025-07-15")).astype(int),
)
return out.assign(
rel_day_post=lambda d: np.where(d["rel_day"] >= 0, d["rel_day"].astype(str), "pre")
)
formula = """effect ~ treat:cohort_0601:C(rel_day_post)
+ treat:cohort_0715:C(rel_day_post)
+ C(unit) + C(date)"""
model = smf.ols(formula, data=df_heter.pipe(feature_eng_event)).fit()
这里 date_0601 把 2025-06-01 cohort 处理前的日期折叠到 control 类别,只让处理后的日期进入交互项。date_0715 也是同样道理。这样做的直觉是:处理前不估计处理效应,处理后按日期估计 cohort-specific 的动态效应。另外,这里的 rel_day_post 把所有处理前时期折叠到 pre 类别,再通过 treat 保证只估计处理后相对时间的效应。实际使用时,也要确认从未处理组不会被误解释为某个处理后相对时间。
cohort-time ATT 聚合
估计出 或 后,我们不能再说模型输出或者计算了一个ATT。我们还需要说明如何聚合。
如果关心 cohort 的平均处理效应,可以写成:
如果关心某个日历时间 所有已处理单位的平均效应:
如果关心整体平均处理效应:
这里的权重 由具体的研究问题决定,常见的做法是按 cohort 样本量或处理后观测数量加权。关键是这些权重应该是非负的,并且解释清楚。这样得到的总体效应才是我们主动定义的目标量,而不是TWFE隐含给出的混合权重。
平行趋势假设
到这里,我们意识到并解决了“TWFE如何错误平均异质效应”,但别忘了,我们还有一条“平行趋势假设"。DID最核心的识别假设仍然是平行趋势。
在错位处理时间中,对 cohort 和时间 ,一个常见的平行趋势写法是:
其中 是处理前的基准时期, 是在时间 可以作为 cohort 对照的单位集合。这个集合通常包括:
- 从未处理单位;
- 到时间 还没有被处理的单位。
关键点是:已经处理的单位通常不应再作为干净对照,因为它们的结果可能已经包含处理效应。
识别 通常还需要同时说明以下条件:
- 无预期效应:,也就是单位在正式处理前没有因为预期处理而改变结果;
- 有效对照与重叠:在每个目标 上,都存在从未处理或尚未处理的可比单位;
- SUTVA/无溢出:一个单位的潜在结果不受其他单位处理状态影响;
- 样本构成稳定:处理前后进入、退出样本的机制不应由处理系统性改变;
- 合理的标准误:若处理在组层级分配,标准误应至少在处理分配层级聚类;聚类数较少时,可以考虑 wild cluster bootstrap 或随机化推断。
如果存在协变量 ,我们可以写成条件平行趋势:
这表示处理组和对照组不需要在总体上趋势完全一样,但在给定协变量后,未处理潜在结果的变化趋势应当一样。匹配、加权、协变量调整和双重稳健DID,本质上都是在努力让这个条件平行趋势更可信。
平行趋势证明局限
平行趋势涉及的是处理后时期的未处理潜在结果:
但这些结果对已处理单位是不可观测的。因此,我们不能直接检验平行趋势。能做的是检查处理前趋势是否支持这个假设。
常见做法是画事件研究图:
若无预期效应且处理前趋势平行,则处理前的 lead 系数应接近0:
但这里要谨慎。处理前系数“不显著”并不能证明平行趋势成立,因为检验可能没有足够统计功效。相反,如果处理前系数已经系统偏离0,那么DID的可信度就会明显下降。
还要注意,在错位处理时间下,朴素TWFE事件研究中的 lead 系数也可能受到其他 cohort 处理后效应的污染。因此,处理前系数图最好使用明确排除已处理对照的事件研究估计器,或者使用 cohort-time ATT 聚合后的事件时间估计。
平行趋势失效
平行趋势失败通常来自以下几类情况:
- 选择性处理时间:增长更快或下降更快的单位更早被处理;
- 随时间变化的混杂因素:例如地区产业结构、人口流入、医院等级变化等同时影响处理和结果;
- 预期效应:单位在正式处理前已经改变行为;
- 溢出效应:对照组被处理组影响,导致对照组不再是干净反事实;
- 构成变化:处理前后样本进入和退出不同,导致结果变化混入样本组成变化;
- 不同的长期趋势:处理组和对照组即使短期看着接近,长期趋势也可能不同。
这六点原因,可以归咎到两点:时间干扰和稳定单元干预假设,用更白话的说,凡是“随时间变化且不同组受影响不同”的因素,都可能破坏DID。