
笔记
因果推断(10)——Meta-Learner
元学习器 Meta-learner
我们之前用了一种目标转换(F-Learner)的方法来将我们想要估计的量作为预测指标放入机器学习模型,从而得到 。这种方法有个缺点就是增加了估计的方差,在大样本时效果会稍微好点。在这里,我们介绍另外一种方法:元学习器,也叫做Meta-learner.
应注意:
这里的元学习与AI领域中的截然不同,在AI领域里,其是指指让 AI “学会学习”(Learn to Learn)的元学习范式,而在我们因果推断里,其是指组合多个基础模型的高层算法。
这里的元学习器主要有三个:S-Learner,T-Learner,X-Learner
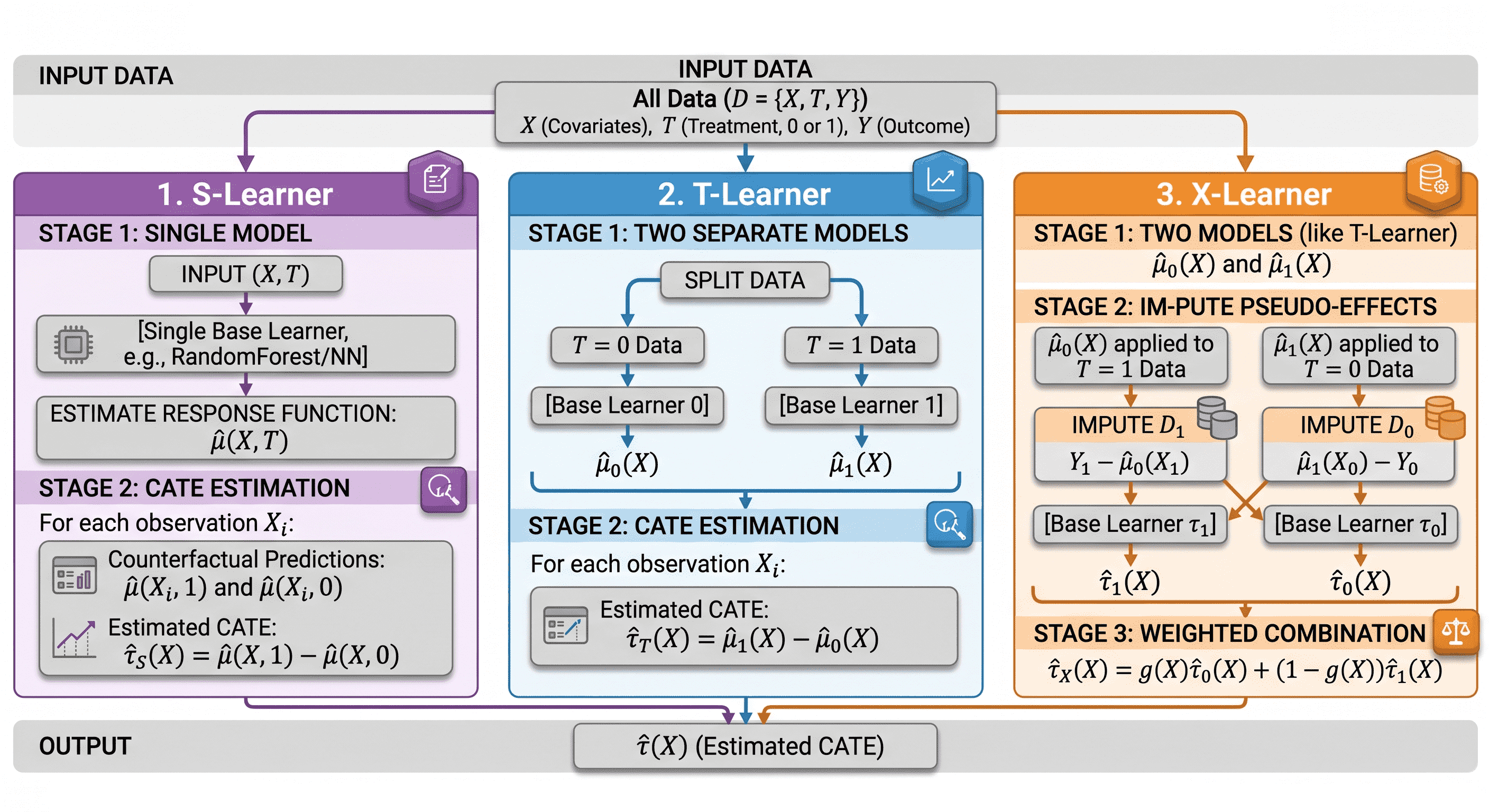
S-Learner
定义:将处理变量(Treatment)与其他特征一起训练,不区分任务层次,使用一个单一的(因此称 S)机器学习模型来估计。
这个很简单,我们之前的机器学习模型里,我们不会将处理变量 一并放入模型,现在,我们只需在预测结果 的模型中将处理作为一个特征加入即可。
然后,我们可以在不同的处理状态下做出预测。预测值之间的差异就是我们的 CATE 估计:
我们这里使用LightGBM的算法:
from lightgbm import LGBMRegressor
np.random.seed(123)
s_learner = LGBMRegressor(max_depth=3, min_child_samples=30, force_col_wise=True, verbose=-1)
s_learner.fit(train[X+[T]], train[y])
s_learner_cate_train = (s_learner.predict(train[X].assign(**{T: 1})) -
s_learner.predict(train[X].assign(**{T: 0})))
s_learner_cate_test = test.assign(
cate=(s_learner.predict(test[X].assign(**{T: 1})) - # predict under treatment
s_learner.predict(test[X].assign(**{T: 0}))) # predict under control
)
需要注意的是,S-学习器的表现表现高度依赖于数据集的特点。在实践中,S-学习器由于简单易训练,时间成本低,是任何因果问题的一个良好出发点。不仅如此,S-学习器既能处理连续处理,也能处理离散处理。
S-学习器的主要缺点是倾向于将处理效应偏向零。由于 S-学习器通常使用正则化的机器学习模型,正则化会限制估计的处理效应。而且如果处理变量相对于其他协变量对结果的影响非常弱,S-学习器可能完全丢弃处理变量(由于正则化的原因)。且设置的 越大,其CATE的估计值和真实值的偏离会更严重。
T-Learner
定义:其分别为处理组和对照组训练两个独立的预测模型,即将为每个处理取值估计一个模型 (假设处理是二分类,如果是n分类,则需要根据处理来训练n个独立的预测模型)
我们构建两个因果模型:和
应该注意,我们这里没有把处理变量 像S-Learner一样放进去
所以我们就可以得到:和,通过和。
然后,在预测时,我们可以对每个处理水平进行反事实预测并得到 CATE:
同样的,我们也使用LightGBM框架:
np.random.seed(123)
m0 = LGBMRegressor(max_depth=2, min_child_samples=60, force_col_wise=True, verbose=-1)
m1 = LGBMRegressor(max_depth=2, min_child_samples=60, force_col_wise=True, verbose=-1)
m0.fit(train.query(f"{T}==0")[X], train.query(f"{T}==0")[y])
m1.fit(train.query(f"{T}==1")[X], train.query(f"{T}==1")[y])
# estimate the CATE
t_learner_cate_train = m1.predict(train[X]) - m0.predict(train[X])
t_learner_cate_test = test.assign(cate=m1.predict(test[X]) - m0.predict(test[X]))
T-学习器避免了对弱处理变量视而不见的问题,因为其可以在小样本里更好的拟合模型。
但需要注意的是,由于我们都在一个处理效应的亚组中分别进行模型拟合,样本量减少,容易出现过拟合的情况,模型容易学习到噪声。且其仍然可能受到正则化偏差的影响。
在现实世界里,我们很容易面临一种情况,我们有大量未处理的数据,却只有很少的处理过的数据(因为处理需要花费成本)。此时在非处理数据里,我们就容易捕捉到非线性的情况,导致我们最后算出来的CATE是一个非线性的,这是一个错误的结论。所以T-Learner会面临的问题:未处理组的模型可以捕捉非线性,而处理组模型由于用正则化应对样本小而无法捕捉。如果减少正则化以捕捉非线性,那么样本小又会导致过拟合。
X-Learner
定义: 更高级的元学习器,分三阶段处理:先预估两个模型,计算效果差异,再分别针对处理组和对照组进行插补,最后再训练一个高层元学习器。也有的教材会写成二阶段,将第二个和第三个阶段合在一起
一阶段:
与T-Learner一样,我们将样本按是否接受处理分为两组,并为处理组和控制组分别拟合一个机器学习模型。和 。
与T-Learner一样,我们也没有把处理变量 像S-Learner一样放进模型去训练
from sklearn.linear_model import LogisticRegression
np.random.seed(123)
# first stage models
m0 = LGBMRegressor(max_depth=2, min_child_samples=30, force_col_wise=True, verbose=-1)
m1 = LGBMRegressor(max_depth=2, min_child_samples=30, force_col_wise=True, verbose=-1)
m0.fit(train.query(f"{T}==0")[X], train.query(f"{T}==0")[y])
m1.fit(train.query(f"{T}==1")[X], train.query(f"{T}==1")[y])
二阶段:
我们使用上述模型来填补控制组和处理组的处理效应:(控制组用处理组的模型;处理组用控制组的模型)
d_train = np.where(train[T]==0,
m1.predict(train[X]) - train[y],
train[y] - m0.predict(train[X]))
# second stage
mx0 = LGBMRegressor(max_depth=2, min_child_samples=30, force_col_wise=True, verbose=-1)
mx1 = LGBMRegressor(max_depth=2, min_child_samples=30, force_col_wise=True, verbose=-1)
mx0.fit(train.query(f"{T}==0")[X], d_train[train[T]==0])
mx1.fit(train.query(f"{T}==1")[X], d_train[train[T]==1]);
三阶段:
然后,我们再拟合两个模型,然后通过倾向性评分合成一个来预测这些效应
# propensity score model
g = LogisticRegression(solver="lbfgs", penalty=None)
g.fit(train[X], train[T])
def ps_predict(df, t):
return g.predict_proba(df[X])[:, t]
x_cate_train = (ps_predict(train,1)*mx0.predict(train[X]) +
ps_predict(train,0)*mx1.predict(train[X]))
x_cate_test = test.assign(cate=(ps_predict(test,1)*mx0.predict(test[X]) +
ps_predict(test,0)*mx1.predict(test[X])))
应该注意的是,模型的表现高度依赖于所选的基础机器学习模型,因此针对数据集去多选用不同的机器学习模型去训练是更加严谨且正确的。